


After having been forced to study this subject a little harder
(please see thread https://forum.videohelp.com/topic333501.html?sid=3219e3ecdb111fb5a6c3895b6cb95a20),
I have concluded that the alleged "Unicode-support" in TextSub
and in the SubStation Alpha file formats is lame, to say the
least. As an older member of the VideoHelp community has already
stated for several times, many people do not (want to) understand
very well what the heck Unicode is. I'm afraid many people still think
that being capable to deal with different charsets/encodings simultaneously
is the same as being "Unicode-ready". Not the case. Yes, .SSA files plus
DirectVobSub filter really manage to display different writing systems
at the same time, but actually they do not seem to use Unicode at all for
achieving that goal. In other words, they simply manage to handle several
codepages at the same time --- which is a completely different story,
period. Putting things in a simple way: non-American Western codepages =
one character in one-byte between 80 and FF plus a language-flag, and
CJK codepages = one character in two-bytes between 80 and FF plus a language-flag,
whereas Unicode/UTF-8 = one character in two-bytes from 00 thru FF plus
no language-flag. Web browsers usually have no problem in reading real UTF-texts or
even binary Unicode files, however I still
haven't found a way to make Vsfilter.dll(v. 2.33) show such capability.
The subtitle picture that I posted to the thread mentioned above
was generated with a script that called only two codepages, namely
ANSI(code 0) and Japanese/Shift_JIS(code 128), notwithstanding,
it was able and sufficient to display Greek and Cyrillic characters
as well, simply because basic Greek and Cyrillic characters already
are a subset of Shift_JIS. On the other hand, the picture shown below
was gotten from a script that (appropriately???) called five codepages.
I hope these considerations can be helpful.
==============================================

+ Reply to Thread
Results 1 to 10 of 10
-
-
Midzuki wrote:
I have concluded that the alleged "Unicode-support" in TextSub
and in the SubStation Alpha file formats is lame, to say the
least.Well, now I have to admit I was wrong (but not entirely).Web browsers usually have no problem in reading real UTF-texts or
even binary Unicode files, however I still
haven't found a way to make Vsfilter.dll(v. 2.33) show such capability.
Yes, Vsfilter will interpret correctly UTF8/Unicode SSA scripts,
but only under (one of) the following conditions:
--- UTF sub scripts MUST begin with µ$oft-inventioned "UTF8 ID"
{bytes EF BB BF};
--- Unicoded subtitle files MUST be "little-endian"
{byte-order mark = FF FE};
Besides, every formatting-style would better have its "Encoding" field set to "1"
( = default). In this way, subtitle pics can display ALL printable characters contained in the font Arial Unicode MS without any need to jump from one codepage to another ^_^
Again, I hope this info will be usefull.
======================================= -
Time for another overdue correction:
Not at all. Vsfilter does not care whether the Unicode file is--- Unicoded subtitle files MUST be "little-endian"
{byte-order mark = FF FE};
little-endianed or big-endianed, as long as the first two bytes
of the file are a Byte-Order Mark. And now, at last,
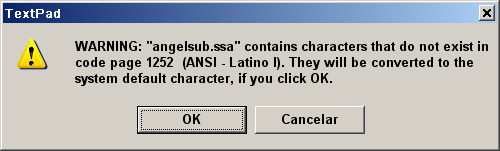
appears the actual source of my current problems with subtiles: TextPad!
The damn text editor by default does *not* write the UTF-8/Unicode BOMs!
The solution I have found: I'm moving to Microsoft's Wordpad!
And here goes the question to the makers of TextPad (Helios Software):
What is the point of opening and saving in UTF-8 or Unicode
if the damn application cannot get rid of the short-sighted limitations of the
narrow-minded and language-segregating codepage scheme?
=================================
-
I must ask:
Why?
Isn't the purpose of subtitles to translate one or many spoken languages into text in the language understood by the viewer?
So: One subtitle file - one language?
/Mats -
It seems there is some misunderstanding, I'm afraid :-(
Of course. Notwithstanding, if when you say that, you mean "subtitle tools thatIsn't the purpose of subtitles to translate one or many spoken languages into text in the language understood by the viewer?
fully-support UTF-8 and Unicode are necessarily useless", then...
I have no idea of what kind of software one'd better use when the goal is
produce subtitles in languages written in Devanagari or similar "exotic" charsets
for example, but I serious doubt you would be able to do it inside the preset
extended-ASCII codepages handled by TextSub and .SSA.
===
-
Ah. Ok. I was under the impression your problem was not to create subtitles with different character sets, but to have multiple character sets in one subtitle file.
/Mats -
That was the problem of the OP that started the threadI was under the impression your problem was... to have multiple character sets in one subtitle file.
and Unicode was created exactly to allow anyone to represent correctly several languages within a same document (OR in a subtitle file, as he wanted).
Regards,
Midzuki.
=== -
I feel interesting that my browser took me here when I was trying to do some studies on the generate code 128 barcode in word. Anyway, this thread do attract my interests, sounds like a good place for me to get some leisure.
-
I'm a MEGA Super Moderator

- Aug 2000
- Sweden



What?Originally Posted by nihenaita
-
Because code 128 encode ASCII Character Set and Midzuki mentioned ASCII. So, google may take you to this site.Originally Posted by nihenaita
 Quote
Quote

Similar Threads
-
How to Convert .SSA/.ASS to .IDX with .SUB?
By rbin in forum SubtitleReplies: 0Last Post: 27th Dec 2010, 22:07 -
How to Hardsub Videos with ASS/SSA?
By rbin in forum Newbie / General discussionsReplies: 0Last Post: 27th Dec 2010, 22:03 -
Problem with SSA/ASS hard subs
By Eva-Unit01 in forum SubtitleReplies: 0Last Post: 2nd Mar 2010, 11:17 -
SSA/ASS capabilities
By tekkyyy in forum SubtitleReplies: 2Last Post: 12th May 2009, 05:31 -
ass and ssa to sub/idx
By MasterRoshi in forum SubtitleReplies: 10Last Post: 20th Jan 2008, 16:31