




I've been working on "CleanSpeech" (a derivative of the freeware Audacity 1.3.0 beta audio editor) with simplified pseudo-scripting to process rather low quality speeches (significant hiss/hum and excessive dynamic range ... whispering to shouting). The end-result is to be a 16kbps .mp3 file for web-streaming at 11025 to 16000 sampling rate.
The script currently includes ClickRemoval + Normalizing + NoiseReduction + TruncateSilence + DynamicRangeProcessing/Leveling + ReNormalization
I'm wondering if it would be advantageous to include ParametricEqualization (or GraphicEqualization).
The main challenge is to reduce the noise enough so that the Leveling/DynamicRangeProcessing can increase the volume of the soft speaking. I can accept some distortion as long as the speaker's voice is reasonably recognizable. I'm ok with that tradeoff in order to clarify the soft speaking that can be nearly 'buried' in the noise.
I've done some testing with different equalization parameters, but I'm not by any means an audio engineer, and not at all clear what I'm doing.
My questions:
* Is equalization appropriate in this situation?
* If so, are there generally accepted parameters to use? For mild to moderate to heavy equalization?
If so, where in the script would it be appropriate to do the equalization? ... before or after the NoiseReduction? before or after the DynamicRangeProcessing?
Here is a link for a typical speech ... 32kbps to be "cleaned up" and converted to 16kbps. Again, my question concerns whether parametric equalization would be advantageous:
http://cleanspeech.sf.net/misc/typicalspeech.mp3
More info -- thanks for getting this far
Here are several scenarios:
* school has backlog of recorded classroom lectures they want to upload to their website for distance learning
* church has backlog of sermons they want to make available for 'distance listening'
In contrast to most users of audio editors for radio broadcast, the speech processing envisioned has these differences:
* noise reduction is a much bigger factor (originals can be ghastly, equivalent to old 'bootleg tapes')
* leveling is a much bigger factor (soft sections made louder and vice versa)
* dynamic range (dr) is the 'enemy'
* dynamic range works well in 'live performance' to hold attention and make points, but can cause big problems for 'distance listeners' ... won't be able to hear the soft sections that are lost in the ambient noise and hiss/hum ... listeners will find themselves reaching for the volume control to manually cut down shouting and boost whispering
* fidelity to original less critical than leveling ... with low quality originals, it is ok to tradeoff better clarity for lower fidelity and more distortion ("that doesn't really sound all that much like Joe ... like maybe he has a cold, but at least I can make out what he was saying")
* truly huge files for the masters and file compression is very important ... end result has to make the best use of 16kbps
* end result is almost always mono
* truncate silence a much bigger issue ... the 'distance listener' can hit the pause button whereas the instructor may be fine with a five minute gap while the lab is prepared, for example.
* end-user doing speech processing often bored volunteer with obsolete equipment
* without scripting, it is error prone and beyond tedious to manually apply the same series of 'effects each time (stereo-to-mono as applicable, .mp3 to .wav as applicable, normalize, click-removal, equalization, noise reduction, leveling, truncate silence, renormalize, resample to 11025, convert to 16kbps .mp3)
* each 'effect' may take several minutes
* manually starting each effect when the previous one finishes is exasperating ... volunteers would prefer to 'kick on the chain of effects', take a break, and come back when it is finished.
* may be dozens or hundreds of 'speeches' to process, so batching is very valuable
For both distance learning and sermons, many of the 'speeches' would share common attributes as far as the noise level and dynamic range used by the speaker. Once noise-reduction and leveling factors are identified, the same factors can suffice for some, many, or most of the subsequent speeches. This can be a huge time saver, and allow overnight processing.
My understanding is that there are well understood and accepted equalization parameters for telephone quality frequency range. My impression is that the above applications would benefit from something similar, but allowing somewhat wider frequency range.
I'm not at all an audio engineer, but perhaps the .mp3 encoder can do a better job with the very limited number of bits (16kbps) if parametric equalization has been done to remove frequencies that don't contribute much to audio clarity. 11025 or 16000 sampling rate with 5khz to 7khz frequency range is the norm.
My experience is that a script with noise reduction and leveling works well, but I want to get guidance on whether to include parametric equalization (peq). For a long speech, adding this to the script can make the processing take that much longer, and I don't want to include it if peq doesn't really help make a 16kbps .mp3 sound clearer during the soft speaking.
A crude graphical representation might look like:
x ..................20hz (-20db)
x ..................40hz
x ..................80hz
xx ................100hz ? begin 'ramp in'
xxx ..............120hz
xxxx ............160hz
xxxxx ..........200hz
xxxxxx ........240hz ? (100%)
xxxxxx ........280hz
xxxxxx ........320hz
xxxxxx ........480hz
xxxxx ..........640hz
xxxxx ..........800hz (mild 'scoop out'?)
xxxxx ..........1000hz
xxxxx ..........1200hz
xxxxxx ........1500hz
xxxxxx ........2000hz
xxxxxx ........3000hz
xxxxxx ........3500hz
xxxxxx ........4000hz
xxxxx ..........4500hz (begin roll off?)
xxxx ............5000hz
xxx ..............6000hz
xx ................7000hz
x ..................9999hz (-20db)
If peq might help, my question could be thought of as "which frequency bands to back off and which, if any, to boost." I'm not clear whether the equalization should be at 100% at 240hz, and how slowly or quickly to "ramp up" from what frequency. Same questions (and ignorance on my part) for rolling off at the high frequencies, given that I've got 11025 sampling rate to work with.
+ Reply to Thread
Results 1 to 4 of 4
-
-
Even with a "perfect" source, your frequency and bit rate s are so low, it is going to be difficult to make anything sound great. Have you looked at Mp3Gain or WaveGain for file normalization ? I believe waveGain also has a built in limiter which is very fast.
Also, sometimes a bit of hiss is preferable to the overprocessed "wooshy" sound of a significantly denoised sound file.
If I have a really horrible sounding source file, I'll apply a "telephone conversation" EQ to it, which does as it says, but it makes the overall sound much more pleasing. I'll check the eq settings if you are interested. It is a preset from a DirectX sound plugin I have. -
I'm not expecting to make it sound great. My main concern is improving the clarity of the softly spoken sections when the original is moderately noisy or worse.going to be difficult to make anything sound great.
Please let me know what the "telephone equalization" is. I can probably take that as a starting point ... and have a preset that isn't so drastic. -
Here's the phone effect on the original MP3, plus a ton of compression as the final "sauce". Dunno if you'll like it, but it sounds easier to make out to my ears.
speech-proc.mp3
This is what the phone EQ curves look like:
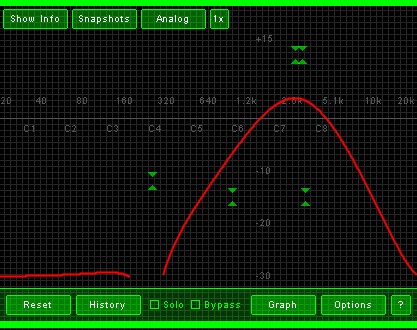
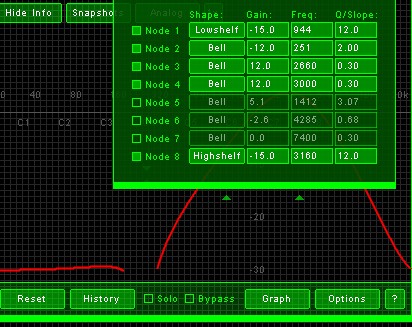

 Quote
QuoteSimilar Threads
-
SubTitle Creation with Speech to Text
By zenzen1 in forum Authoring (DVD)Replies: 7Last Post: 4th Nov 2014, 05:53 -
Easier way to create speech and captions?
By JamesC2000 in forum ProgrammingReplies: 0Last Post: 12th Dec 2011, 05:27 -
Easier way to create speech and captions?
By JamesC2000 in forum Newbie / General discussionsReplies: 0Last Post: 6th Dec 2011, 11:18 -
5.1 to stereo with speech norm
By Voxel in forum AudioReplies: 12Last Post: 8th Nov 2011, 10:15 -
speech bubbles
By psydkick in forum Newbie / General discussionsReplies: 7Last Post: 7th Jun 2009, 22:46