




Just out of curiosity, does a still-image or video compressor that uses reference points + gradients to recreate a content exist?
Let's take for example the JPEG format. I don't know exactly how it chooses what to do with a picture, but I know that at low quality settings, a picture of a sky becomes very "blocky". Have a look at this picture to be sure of what I mean.
Well, I was thinking of an algorithm that could instead locate what I'll call "reference points", i.e. points of a specific color at the center of a certain picture area and then, on the decoding phase, draw a gradient between each of those reference points, creating gratuated shadings instead of blocks.
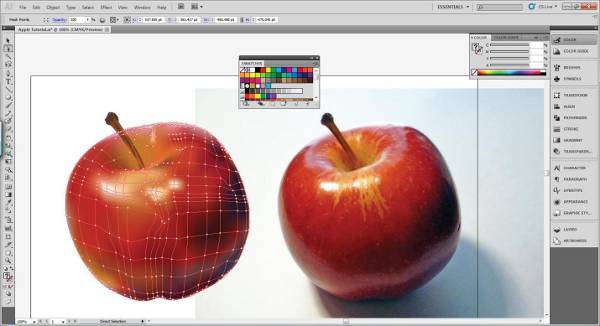
Something similar to Adobe Illustrator gradient meshes:
(main article: http://garmahis.com/tutorials/illustrator-gradient-mesh-tutorial/ )
Actually I was thinking of using less points, just the ones in the centers of each area of a prevalent color inside a picture. Not a grid/matrix of always x*y points (that would be much more numerous; you see the Illustrator gradient mesh: it's a grid, even if each intersection/point can be moved around; the total number of pixels is fixed: x*y). I'm thinking, instead, of just a bunch of points put in the proper places, where they really need to be (have a look at the pictures below, it'll be clearer).
And for movies, the codec would only track the movements of those points (or appeareances of new ones and disappeareances of no more necessary ones), exactly like vectors move areas of pixels in the codec that I know something about (h.264).
I'm not talking of something like this: http://techreport.com/news/24058/researchers-demo-vector-based-video-codec since this is based on contours (although it's very fascinating to me, at a first glance).
I'm talking of something like this:
Yes, I know that this face is iper-blurry, but I made the picture myself just to let you better understand my idea.
You'd probably say "but we'd need a zillion points to have a sharp image". Not exactly. The number of points would be surely less than the number of pixels that make the original picture, but the "spatial" gaps/transitions between each reference point would be entirely filled up by a generated gradient and we would have no blocky area (like we have in JPEG or MPEG).
Obviously, areas richer in details would require more references points, but shaded areas, like skys, clouds, walls, blurried backgrounds or any solid colored object or body with shadows would be recreated with a little bunch of points instead of many pixels or blocks of square gradients like in JPEG or colored squares (blocks) like in MP4.
Another idea could be using both reference points and reference vector lines, in relation with what it'd be better for each picture portion. Something like this:
One more idea could be using timed progressive changes of the color of each reference point (for example: at frame 7 the A point is #FFFFFF, and gradually becomes #FF1177 at frame 129, recording only this two values and generating the intermediate colors during this lapse of time with an algorithm).
Ok. Here's the question again: does a codec that uses any of the ideas I wrote about above exist at the moment?
Thank you for your patience.
+ Reply to Thread
Results 1 to 20 of 20
-
Falco2000, video newbie.
Let's everyone help each other. -
for image compression: the first thing that comes to mind is SVG
for video: it sounds like object based coding (purposed for MPEG-4, but afaik never implemented); basically the idea is to have object for everything and render the stuff like when using a 3d renderer
first few problems that come to mind:
- creation/manipulation/compression of the formulas that hold the gradient information
- need for highly detailed 3d images of the object as basis
- de-/encoding speed and requirements
-------------
Problem is Reality mostly consists of detail rich content and btw. most people are happy with gradients in MPEG-4 if 10bit internal precision is used. (like you can use with MPEG-4 AVC High10&Co profile, H.265 also supports 10bit internal precision)Obviously, areas richer in details would require more references points, but shaded areas, like skys, clouds, walls, blurried backgrounds or any solid colored object or body with shadows would be recreated with a little bunch of points instead of many pixels or blocks of square gradients like in JPEG or colored squares (blocks) like in MP4.
Cu Selur - creation/manipulation/compression of the formulas that hold the gradient information
-
The problem is that I can't understand why should we use a deblocking feature/filter to blur the blocks, when the "blocked" area could be -beforehand- rendered with a gradient instead.
If one needs a thing named "A", he/she should logically use a method to do the thing "A", not a method to do a thing "B" and later apply a second method to transform "B" in "A". Falco2000, video newbie.
Falco2000, video newbie.
Let's everyone help each other. -
a. H.264 (and a bunch of other newer codecs) use inloop deblock filter, which are ment to be used since the encodec assumes that they are used. -> disabling the deblocking for those codecs is a bad idea
b. lossy block based codecs naturally create block based artifacts; e.g. wavelet or fractal based codecs simply produce other artifacts; that's the price of being lossy. Being lossy always implies that errors are made and that these errors are visible some way or the other. For your purposed format lossyness would probably (like for wavelet based codecs) show in a loss of detail.
=> if don't want to use blur/deblocking/smoothing and other techniques to mask compression artifacts live with the size reduction lossy compression offers.
It's not a problem to avoid blocking&co in general, there are lots of lossless compression techniques. The problem is to compress the material and keep the as much quality as possible.
From time to time there are new/alternative approaches (e.g. http://www.bath.ac.uk/news/2012/12/11/pixel-die/) but most tent to die rather quickly.
-
It's essentially the same thing. Except in the case of deblocking (eg h.264) the reference points are on a simple rectangular grid (for computational efficiency in both the encoding and decoding).Originally Posted by falco2000

-
You mean vector graphics? That's already being used in animation -- see adobe flash for example.
I'm convinced that we will eventually move into an era of vector based "video" interpretation for chrominance and luminance, motion (no frames anymore) perhaps depth and other factors I can't even imagine. Whether it's based on linear or logarithmic grids or fractal constructions, who knows? iPhone video and FCPX are baby steps in that direction. Whomever figures this out will be known in history as the poor schlub that had his genius ideas stolen and exploited.
Edit: Should have looked at selur's link before posting -- that's the kind of thing I mean! -
Ahhh, that's where they are heading,..FCPX are baby steps in that direction.
-----
I'm very skeptical regarding vector based compression for real life footage, but time will tell. (next video formats to come are H.265 and VP9) -
I think so. Even Apple wouldn't be so boneheaded as to piss off that many customers that completely without some larger purpose. CFR video is on its way out.Originally Posted by Selur
Variable frame rate video already has advantages in terms of exposure and transmission bandwith. Current interframe compression schemes such as h.264 already handle motion differentially within and between frames. Various delivery platforms require multiple sizes and frame rates for identical material (i.e. The Hobbit, YouTube.)
Right now dealing with VFR Variable Picture Size material is a pain because our aquisition and manipulation systems -NLE's- are frame/pixel based. Apple is jumping ahead of the curve and (I believe) hiding their intentions in plain sight.Last edited by smrpix; 9th Jan 2013 at 12:03.
-
Here's my take on it:
You've got dumb computers on one side that do very well and very quickly with simple concrete items (even many of them).
On the other side, you've got human brains that do fair with CONCRETE items (up to a point of speed & number), but can also do very well with ABSTRACT items.
You can bridge the 2, but it takes EFFORT.
Take for example the case of still images:
Native formats generated by cameras, scanners, etc are all CONCRETE points on a bitmap because the imaging chips' brains are too dumb to "understand" that a certain object is an wet, maroon umbrella in the shadows. What does UMBRELLA mean to a chip? or Wet? or Maroon? But it can easily do pointillistic dots until the image equates to what we accept as the object.
Computers can also use file formats with an abstract language, but they are based on structures consisting of geometric primitives and boolean and other tricks to give a composite that also equals an object.
Yes, it would be fairly trivial to create a generic "umbrella" object, even one that had a maroon coloring with gradient. But what about the aspect/perspective, the weathering, the lighting, etc? That makes this simple geometric object MUCH MUCH more complicated. Still might be less in size than the concrete, but once you start being very exacting in the specifics it makes the size grow until it isn't THAT much smaller.
Now, try to take a concrete image and translate it into an abstract image. You would do this with still imaging by tracing...
Try to trace this "wet, maroon umbrella in the shadows" image and leave enough mesh points for it to be realistic at life size, and layer the object with the correct gradients to get the lighting right (or convert to 3D and add lighting objects). Does it MATCH the image? Get more painstaking until it matches.
How long would it take to get it EXACT enough to pass as a duplicate of the bitmap version?
Now, try to do that for a complicated image that has many, confusing objects in the frame...
Now, try to do that for images over and over again and only give yourself 1/60th of a second to get it exactly right...
That is the obstacle that we would have to overcome before ABSTRACT imaging could replace CONCRETE imaging.
And that has to do with pattern & object (incl. motion) recognition, and a "world view" library of pre-recognized objects and definitions all of which would need to have been developed and be usable in realtime fast enough to create an abstracted image. This is the role of AI, and we still have LOOONNNGGG way to go in that area.
BTW, I believe VFR & Var. Pic Size might help us learn tricks to speed up the recognition/translation portion, but AFA working better with CONCRETE imaging, they are red herrings that will just make everyone's life MORE complicated. VFR already shows up on this website time and again as one of, if not THE main culprit of problems involving editing/playback of files. Only when most all CE and PC devices are built from the ground up with a foreknowledge of VFR, VPS, Var. Window shape, or any other kind of semi-abstract feature (and the horsepower to handle them fluidly in realtime) will they ever become a benefit. Even that is a long way down the road. And CFR is NOT on it's way out by any means.
Besides, there is the area of Holographic imaging (which is a type of concrete image) that will probably raise the bar of computation that much farther prior to getting to abstract imaging.
My guess is that abstract imaging will still have a niche (scientific, vertical market) use for probably MY LIFETIME.
Scott
BTW, this is just a portion of a more universal treatise on Abstract vs. Concrete media (part of working on that TTS/Singing computer effort that I referred to recently) that I developed a few years back. While I've made a few additions, nothing I postulized then has had to be retracted.Last edited by Cornucopia; 9th Jan 2013 at 18:12.
-
Cornucopia,
While full AI/discreet objects mode may be where we eventually end up, I don't think it's necessary to go whole hog to leverage vector motions. The construction of images out of pixels, or silver granules happens in the mind. A dumb but fast computer only has to know there is A color/luma differential between B and C points over D time. Various slow motion algorithms, for instance, already use this kind of interpolation (more or less succesfully.)
I'm just suggesting that going forward we will see greater plasticity of frame rates and pixel mapping.
It's already happening. Look in these forums the last few days and you can see folks having issues with VFR, phones held sideways, and someone (ironically) trying to datamosh i-frame video. CFR, like black and white, once a necessity, will become a special effect.
I don't think we're in any profound disagreement on this, its mostly a question of timing.
Steve -
I agree, it's a matter of timing. A LOT OF TIME, to be precise and honest.Originally Posted by smrpix
Regarding constant-frame-rate especifically, there are one zillion tons of hardware that was designed to work with fixed refresh rates, to begin with. Between the CFR "past" and the VFR "future", there will be a veeerryyy loooong (and UNcertain) *moment of transition*.
-
[QUOTE=El Heggunte;2211968]
Like FCPX?Originally Posted by smrpix
-
Looks like we're going off topic (again) oh well...
VFR video has been around years, it's nothing new. Yes it's more efficient, but it will always be an end delivery format. NLE's will never deviate from a CFR timeline. At best they will become "VFR aware" and convert to CFR before you place clips on a timeline, either explicitly or "behind the scenes" without user knowledge. This means they will introduce duplicates where the frame rate drops in the timecode to conform to the base CFR (ie. the way we treat it right now in other programs before importing into a NLE) . The reason is when you mix 2 videos with different VFR timecodes it will be impossible to edit; only by conforming to a common time base reference can you mix videos. The other problem is there is no perfect way to convert to CFR, they will always be slight sync errors. This is why it will never be introduced into Pro NLE's as a preferred workflow (yes you can edit it, but why when you have a CFR choice and no sync error) -
poisondeathray--
That's why the actual motion will have to be vector-based (or whatever it will be called) before it can be well-implemented. And I think it will. I'm not advocating for this or anything, I just think that's the way its going.Last edited by smrpix; 9th Jan 2013 at 17:13.
-
Originally Posted by smrpix
We use motion vectors now.
If you meant vector based coding and scalable algorithms - they are far too less detailed and computationally heavy to be useful . Some one posted an article recently about using a GPU farm to make it usable, but image quality is very poor compared to what we have now or even 2 years ago. I don't think there is any future in that beyond video games and maybe some anime content. Hopefully someone will develop something extraordianary and usable and prove me wrong, but the way things work now I don't see it happening
VFR will always be used as an end delivery format (like it is now), because it's more efficient. It will never be a preferred means of acquisition . Note I'm talking about timecodes VFR like those used in portable devices like phone cameras, not the "pro VFR" versions used like in Varicams. The difference is 1st type of VFR has dropped frames, timecodes tell the player or playback device to speed up or slow down in sections. The 2nd type is really a CFR stream, it has frame duplicates and various cadences for overcrank and undercrank -
To clarify, I mean vector-based motions as in flash animation where a starting point, an ending point, a time period and acceleration can be defined and it will play it back accurately based on time rather than number of frames. (That's why this conversation isn't COMPLETELY OT.)
Varicam and other high-speed video, as you point out, acheive their effect by using an accelerated CFR and that's obviously already here and in regular and creative use.
From (my projection of) Apple's perspective, I'm sure there's a good deal of money to be made by revolutionizing and patenting video aquisition, manipulation and delivery. -
Where in FCPX is there anything "revolutionary" regarding VFR? I'm looking, I just don't see it.
Well said, pdr. I think we're on the same page.
Also, not wanting to start a flame war or anything, but let me just show my age and tell you how silly I think datamoshing is. It's visual teen masterbation along the lines of a "collage" or someone who is trigger-happy with the NLE's FX buttons. Art? Show me one real good example...
Scott -
[QUOTE=smrpix;2211971]
No, but like a type of hardware I haven't heard of yet. Sorry, I really should have been more clear:Originally Posted by El Heggunte
VFR-stuff cannot "do its best" while there is no such thing as Variable-REFRESH-Rate.
-
I'm completely with you on this one -- and probably very close to your age -- and location -- north-eastern Illinois for me.Originally Posted by Cornucopia
I don't want to get into a war either. I'm an old Avid guy myself, but I see some writing on the wall in Premiere, FCP and Vegas being raster size and frame rate independent. Baby steps, man. -
Compositing apps have almost from early on been raster size independent (and better with framerates, too). Editing REQUIRES a more locked-in approach (at least at this point).
Yes, while I use any and all NLEs to get the job done (and most all of them are decent, some have different strengths & weaknesses), if I had a high demand, quick turnaround tv series or feature multi-user burden, I'll be going to the AVID.
I think we can make do with things like delta frames and motion vectors & interpolation for a while and still use CFR. It's got a long life ahead. I don't hate the idea of VFR, but lots of other infrastructure really has to be in place before it is as transparent a user experience for everyone as CFR is (and that's where my priority lies).
Scott


 Quote
QuoteSimilar Threads
-
What is the right reference volume
By warrandeb in forum AudioReplies: 10Last Post: 26th Sep 2012, 09:41 -
MKV Reference File
By coolguygwh11 in forum Video Streaming DownloadingReplies: 2Last Post: 16th May 2012, 15:41 -
H.264 reference frames
By grinder_luck in forum ProgrammingReplies: 1Last Post: 13th Jul 2011, 12:39 -
How to reduce "striped gradients" in too-compressed videos?
By Greycat in forum RestorationReplies: 9Last Post: 24th Jun 2010, 16:43 -
MXF with JPEG2000 codec in Mainconcept Reference
By lord25 in forum Video ConversionReplies: 1Last Post: 3rd Nov 2009, 10:34