




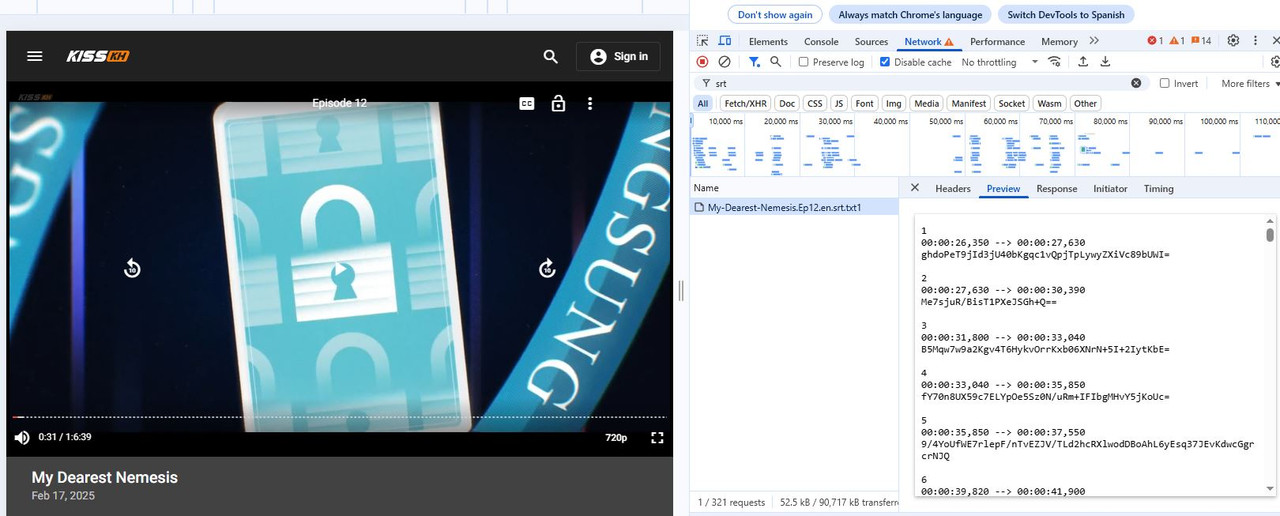
I'm trying to extract the subtitles from this website... but they are displayed like the image.. could someone help me..
https://kisskh.co/Drama/My-Dearest-Nemesis/Episode-12?id=10170&ep=178314&page=0&pageSize=100
Thanks in advance
+ Reply to Thread
Results 1 to 5 of 5
-
Last edited by sekininsha; 23rd Jun 2025 at 23:34.
責任者-MDX -
I found this guide of: 2nHxWW6GkN1l916N3ayz8HQoi , https://forum.videohelp.com/threads/417527-help-in-decrypting-the-subtitle#post2766956
I'll put it into practice... if anyone knows another method I would appreciate it.責任者-MDX -
https://www.swisstransfer.com/d/57d2324c-4a8a-464a-9e7f-1136653ea0beOriginally Posted by sekininsha

-
this is the interesting part
We have an obfuscated function responsible for decrypting encrypted texts in subtitle files:
After analysis using Chrome DevTools, we identified it uses the following array:Code:function _$af182998(n, e) { if (jso$ft$uoel$_33(jso$ft$giden$window()[_$_7270[3]][_$_7270[2]][_$_7270[1]](_$_7270[0]))) { return _$_7270[4] } ;var i = jso$ft$giden$JSON()[_$_7270[6]](jso$ft$giden$atob()(_$_7270[5])); return e[_$_7270[12]][_$_7270[11]](n, e[_$_7270[8]][_$_7270[7]][_$_7270[6]](_$_7270[10]), i)[_$_7270[9]](e[_$_7270[8]][_$_7270[7]]) }
After deobfuscation, the function becomes clear:Code:_$_7270 = [ "kisskh", "includes", "href", "location", "k-i-s-s-k-h.-l-a", "eyJpdiI6eyJ3b3JkcyI6WzEzODIzNjc4MTksMTQ2NTMzMzg1OSwxOTAyNDA2MjI0LDExNjQ4NTQ4MzhdLCJzaWdCeXRlcyI6MTZ9fQ==", "parse", "Utf8", "enc", "toString", "AmSmZVcH93UQUezi", "decrypt", "AES", "k-i-s-s-k-h.-c-o", "eyJpdiI6eyJ3b3JkcyI6Wzk0Njg5NDY5NiwxNjM0NzQ5MDI5LDExMjc1MDgwODIsMTM5NjI3MTE4M10sInNpZ0J5dGVzIjoxNn19", "sWODXX04QRTkHdlZ" ]
Function Workflow ExplainedCode:function jso$ft$uoel$_33(a) { return !a } function jso$ft$giden$window() { return window } function jso$ft$giden$JSON() { return JSON } function jso$ft$giden$atob() { return atob } function _$af182998(n, e) { if (jso$ft$uoel$_33(jso$ft$giden$window(), location.href.includes("kisskh"))) { return "k-i-s-s-k-h.-l-a" } var i = jso$ft$giden$JSON().parse(jso$ft$giden$atob("eyJpdiI6eyJ3b3JkcyI6WzEzODIzNjc4MTksMTQ2NTMzMzg1OSwxOTAyNDA2MjI0LDExNjQ4NTQ4MzhdLCJzaWdCeXRlcyI6MTZ9fQ==")); return e.AES.decrypt(n, e.enc.Utf8.parse("AmSmZVcH93UQUezi"), i).toString(e.enc.Utf8) }
1. URL Verification:
- Checks if current URL contains "kisskh"
- Returns fixed fallback text (`k-i-s-s-k-h.-l-a`) if verification fails
2. IV Preparation:
- Decodes base64 IV string to JSON:
- Represents 128-bit IV for AES-CBC mode
3. Key Preparation:Code:{ "iv": { "words": [1382367819, 1465333859, 1902406224, 1164854838], "sigBytes": 16 } }
- secret key: AmSmZVcH93UQUezi
- Converts to UTF-8 format using cryptoModule.enc.Utf8.parse()
4. Decryption Process:
- Uses AES mode
- Inputs: Encrypted text + Secret key + IV
- Output converted to UTF-8 string
decryption process in python:
https://gofile.io/d/NVqvZECode:#pip install pycryptodome, requests import requests from base64 import b64decode from Crypto.Cipher import AES from Crypto.Util.Padding import unpad import re import os def decrypt_subtitle(encrypted_b64): SECRET_KEY = b"AmSmZVcH93UQUezi" IV_WORDS = [1382367819, 1465333859, 1902406224, 1164854838] iv_bytes = b''.join(word.to_bytes(4, 'big') for word in IV_WORDS) try: encrypted_data = b64decode(encrypted_b64) cipher = AES.new(SECRET_KEY, AES.MODE_CBC, iv_bytes) decrypted_padded = cipher.decrypt(encrypted_data) return unpad(decrypted_padded, 16).decode('utf-8') except Exception as e: print(f"Error {e}") return "" def download_and_process_subtitle(url, output_file): try: response = requests.get(url) response.raise_for_status() subtitle_content = response.text processed_lines = [] segments = re.split(r'\n\s*\n', subtitle_content.strip()) for segment in segments: lines = [line.strip() for line in segment.split('\n') if line.strip()] # if len(lines) < 3: # continue segment_num = lines[0] time_range = lines[1] encrypted_text = ''.join(lines[2:]) decrypted_text = decrypt_subtitle(encrypted_text) processed_lines.append(f"{segment_num}") processed_lines.append(time_range) processed_lines.append(decrypted_text) processed_lines.append("") if processed_lines and processed_lines[-1] == "": processed_lines.pop() with open(output_file, 'w', encoding='utf-8') as f: f.write('\n'.join(processed_lines)) print(f"saved in: {os.path.abspath(output_file)}") return True except requests.exceptions.RequestException as e: print(f"Error: {e}") except Exception as e: print(f"Error: {e}") return False if __name__ == "__main__": subtitle_url = "https://sub.streamsub.top/One.High-School-Heroes.2025.Ep8.en.srt.txt1?v=qv2hnadrsft" output_filename = "subtitle.srt" download_and_process_subtitle(subtitle_url, output_filename) -
Thanks everyone... well yes both methods work ... yes
@slayer36 Thanks for the help... I finally managed to do it...
@imr_saleh ... Thanks for the analysis and this very good and fast solution above all.責任者-MDX

 Quote
QuoteSimilar Threads
-
TS-Doctor - How to extract subtitles from .ts ?
By vhwul62 in forum SubtitleReplies: 8Last Post: 31st Jan 2023, 08:00 -
Extract subtitles from a dvd
By LucaGua81 in forum SubtitleReplies: 5Last Post: 21st Jan 2023, 12:54 -
How Can HardSub Subtitles Extract?
By cinamews in forum SubtitleReplies: 7Last Post: 25th Sep 2022, 06:33 -
Does anyone know how to extract subtitles from .ts?
By ALUOp in forum DVB / IPTVReplies: 48Last Post: 27th Jul 2022, 00:39 -
Subtitles to extract
By ecolek in forum Video Streaming DownloadingReplies: 2Last Post: 14th Feb 2021, 05:45