


This as a general discussion thread about neural network scalers. I'm calling them "NN scalers" for short. Some of them are single image applications that aren't supposed to be for video, but can be "abused" to use on video such as Topaz Gigapixel AI, Remini, ESRGAN, RAISR, FSRCNN, etc... The older NNEDI/2/3 also falls under this definition. Some have been trained specifically for video and multiple frames like Topaz Video Enhance AI, TECOGAN, SOFVSR . The Topaz offerings are commercial, but there are many free NN scalers and research projects on github that are usuable in python , usually pytorch or tensorflow. A partial list with links ( https://github.com/LoSealL/VideoSuperResolution ). There is lots of info and resources, written guides and video tutorials on youtube - just search google.
My overall impressions for NN scalers in the video context - it's mixed. Sometimes it works well in limited conditions , other times poorly, other times not much better than a traditional workflow. I've been testing these for about 2 years and I'll post more details about pros/cons, potential usage cases, short sample tests - sources, outputs and analysis over the next while.
I'd love to hear about other people's experiences with NN scalers, but please "flesh out" the descriptions with samples of sources and outputs. What types of material did the model/framework work well on? Where did it perform poorly? etc...
I'll start with a reply to a post from another thread
https://forum.videohelp.com/threads/399360-so-where-s-all-the-Topaz-Video-Enhance-AI-d...e3#post2603010
Originally Posted by johnmeyer
Some of them can - Resolution charts are sometimes the wrong "measuring stick" for this.
We use various zone plates, test charts etc... because they are good at measuring how imaging systems and traditional scaling algorithms perform. These tests are strong predictors of actual results "in the field." They have high correlation, and are consistent in virtually all real world situations, so the results are generalizable. eg. There is only a fixed maximum amount of resolution a sensor/lens combo can potentially resolve under ideal conditions. Nothing more, Period. eg. We know bilinear interpolation which samples a 2x2 pixel grid always produces softer results than say, bicubic which takes into account 4x4, or lanczos3 always produces sharper results than the earlier two (and it produces halos and sharpening artifacts), because the math says so, and the charts confirm it. It's science, math and predictable.
Deep neural network scalers throw this line of thinking out of the window, because they can "cheat". The problem is that the correlation between NN test charts results applied to other situations is not necessarily that high compared to a traditional scaling algorithm like bicubic, or lanczo3, etc...
Models generally only work well when used on similar material and conditions as their training set. A model trained specifically on test charts can definitely reconstruct patterns to "increase resolution" - but that might have limited applicability - that NN scaler might fail miserably on other real life situations and patterns. Conversely, a model trained for something else might fail miserably on a test chart, but look great on that other content. e.g. A model might be trained to recognize tight curly hair in random directions, or tissue paper microfibers aligned at seemingly random angles, or human skin pores - those sort of patterns are not represented well by typical test charts (trumpets, wedges, lines, circles). Even though that chart might measure "x" lines of horizontal or "y" lines of vertical resolution; on those other types of shots, the NN scalers can sometimes "cheat" and "jump" to some higher effective resolution. On the other hand, certain cues can cause them to "misfire" or "jump to conclusions" and join lines or make connections that they really shouldn't. Some smudge or pixel at the wrong place can cause some of them to create artifacts and reduce the effective resolution. Sometimes there are weird artifact patterns generated (not just typical moire, aliasing) where you do not expect them to be. The increase or decrease in resolvable detail is not necessarily a linear function with NN scalers - you can get gaps where it unexpectedly gets better when you expected it to get worse, or vice versa. For artifacts, you can retrain the model on a different larger data set, and it can improve or fix them - but if you train it in one direction, it can get worse on other types of content. Everything is less predictable for NN scalers than traditional scalers. Various test charts (not just resolution, other patterns) can still provide some useful information on NN scalers, but they do not necessarily have as strong predictive or generalizable value when NN scalers are used - so you have to be careful about interpretation and application of the results.
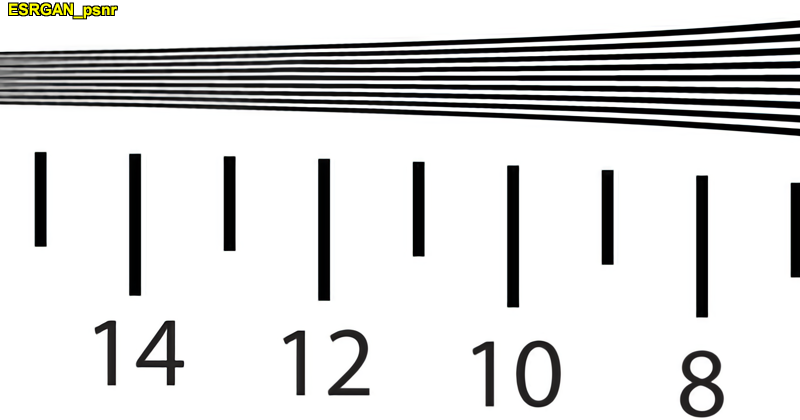
I don't have a chart specific trained model handy, but a "generic" model can still increase the resolution significantly. The attached zip has crops from an ISO12233 chart , it has the cropped individual horizontal,vertical output images for ESRGAN_psnr, lanczos3, nnedi_rpow2(cshift="spline36resize"), and the original src. Free free to test other scalers.
Here is an animated png preview (might not animated in some browsers) of a horizontal res crop
Make sure you view the attached zipped images at 100% .
For both horizontal and vertical resolution, lanczos3 has aliasing beginning at ~900L/PH and clear aliasing at ~1000 L/PH on diagonals. On the higher res pattern, it confirms ~900 L/PH. Note the concentric rings pattern is aliased as well. Numbers have ringing artifacts
NNEDI3_rpow2 has better horizontal resolution in this test than lanczos3; it has less aliasing and sharpening artifacts than lanczos at ~900 L/PH diagonals, but vertical shows some early contamination patterns at lower resolutions. Concentric rings have bizarre artifacting at NE , NW (compass reference). Numbers are more clear than lanczos
People will argue over what the exact L/PH values are for the results, but nobody would argue that ESRGAN_psnr has "increased" the "resolution." Everything is more clear and crisp; there is less blurriness, less aliasing, less ringing. It almost looks "vectorized". These results are simply impossible for a traditional scaler or any traditional filtering workflows. Horizontal ~1400-1450 L/PH. Vertical is a bit less ~1350-1400 L/PH. Clear circlar pattern, clear numbers.
You can demostrate this "magic" on different types of test charts. If you specifically train a model for specific charts, you can improve the results farther.
Later I'll post some non test chart examples where some of these newer NN scalers can definitely increase resolution over some traditional methods, and reach closer to the ground truth, including closer examinations, metrics such as PSNR and VMAF, and artifact analysis.
+ Reply to Thread
Results 1 to 9 of 9
-
-
warning long post

In general, I find there are 2 situations where some of the deeper NN scalers can sometimes perform significantly better than "traditional" scalers or workflows when used properly. 1) Certain types of animation, anime, cartoons, game textures 2) High quality live action ("real life") material derived from a clean downscale. Notice there are "only" 2 scenarios listed - But that has more to do with the datasets the models were trained on. They can work well in other situations - if they've been trained for that specific situation. Just look out for artifacts.
Anime/cartoon/video game texture models are available because they are popular with geeky tech people and there are forums dedicated to these and upscaling models. For the 2nd case, most reseach papers train using a clean image dataset HR reference, and a bicubic or similar downscale for the LR, instead of a degradation route where you thrown in some compression artifacts and noise issues. Model availability and training tend to limit real usage scenarios. Training a specific model can take a long time, and if you use a wrong model for your situation you will get poor results. Some models are not publically available, or held in closed groups or forums. Some come with commerical software like VEIA.
But it's usually a crappy, low quality SD version that people want to upscale; not some clean good quality SD source such as case (2) - and there aren't very many trained models for that low quality source scenario. A big problem is there are many, many different categories and degrees of "noise". It's a huge category, and you can't train something that is good at everything - there are always tradeoffs. A model trained to remove coarse heavy grain will not perform as well on fine dancing grain, or chroma noise, or some other type. Also, it's difficult to isolate "noise" from "signal" without degrading "signal". It's very easy to overdenoise and smooth over actual details; it's a very fine line, and models generally have limited control over this. That's one of the reasons why there is so much variability in the quality of results posted by people - that x/y/z/MQ/LQ/whatever model wasn't trained for that type of noise - and you're not getting ideal results. It's much easier to train cleanly downsampled images, and that's why you see 9/10 research projects using that method. The ones that can handle noise are usually cartoon/animation/anime models, where you can get away with denoising more; and you actually want to denoise for certain art styles.
VEAI has models like Artemis MQ (MQ meant for Medium Quality sources) that were trained on those intermediate (not-clean) situations like some DVD's which usually have some noise & grain. My results on typical DVD material using VEIA weren't great so far - they don't look much better than what you'd get with a traditional workflow. Some results that people post look quite poor - although some of them had easily identifiable preparation mistakes. Others were oversmoothed and oversharpened to the point it looked like a water painting (on live action content, not "cartoons"). Generally there is some denoising , some sharpening and some objects are more clear, but sometimes lots of artifacting or patchy denoising. There is so much variability in the results, it's quite inconsistent - and you would expect that to an extent because there are so many different types and degrees of noise and grain. Some results that people post looked good on screenshots - but if only a screenshot is posted , or some youtube video - that's not enough for a proper analysis. Maybe there are other flicker or temporal problems in the next frames. Maybe youtube's compression smoothed some of the artifacts over. Maybe some other traditional method, or model, or framework does a similar or better job but faster. Maybe people don't have good eyes and can't see the artifacts, maybe they don't have background experience with video. It would be nice to understand why there are so many mixed results, and it would help if people are posted more complete information such as samples of source, version numbers, steps in the workflow, samples of the output (not youtube). Some people swear a certain older version was better , maybe because of model regressions, yet others think another newer one is. There are so many unsubstantiated opinions because...almost nobody posts complete information. This area needs more investigation - If you can identify the conditions a certain model works well in, or which situations cause problems for it - then maybe models can be improved with the feedback with more training; or new subsets of models can be generated for more specific situations. e.g. "coarse grain" MQ model, vs "fine grain" MQ model, vs. "dancing grain" MQ model. vs. "mild MPEG2 macroblocking" MQ model, etc... Eitherway, having more models to cover more situations is a good thing, and at least Topaz are trying to improve things.
There are pros/cons to all of these scalers. There are some good results coming out of VEIA - I can confirm that. Many of the poor results posted are from people not pre or post processing them correctly. But there are some bad unusable results too, despite doing everything right - that's the way it is with NN scalers - sometimes it works well, sometimes it doesn't. Lots of upside, lots of downside should be the motto. YMMV.
In order to use any NN scaler properly (including VEAI), you must
1) pre process correctly for that situation. eg. If they are applicable, things like IVTC , or deinterlace if interlaced content, denoise cautiously (eg. if the model you're using has not been trained to handle that type of noise). Try to use lossless workflow as much as possible in/out of the scaler - eg. many of the early VEAI examples posted used crappy compression. If you have VFR material, you're not going to want to process duplicate frames, it's a waste of time.
2) use a correct model for that situation . Or use (1) to "massage" or filter it to make it suitable for how the model was trained. A specific model trained for a specific situation will always produce better results. Wrong model for given situation = bad results. e.g. if you use a model trained on clean downscaled 8k DSLR images, it's not going to work well on a VHS source. I've tried stretching the usage definitions and it never ends well. Models are quite narrow in their appropriate usage, defined by their training set. And ones that were trained on diverse material tend to be mediocre - you'd probably get better results using traditional workflows (and they'd be faster)
3) post process the issues that invariably arise from (2) . The majority of NN scalers are spatially trained on single images sets, so often you get flicker artifacts and feature inconsistencies. Some sharpen or enhance noise, so you might have to denoise. Some soften and denoise, you might have to sharpen. It's rare that something works ideally right "out of the box." You can often improve it farther with some type of post processing
The main difference between these newer generation NN scalers, is the ability to scale with higher frequency, finer details (if/when they work well). They can sometimes pass for real HD, instead of what looks clearly is a SD upscale. Details and lines are fine, not coarse and thick. eg. You can make out individual fine hair strands, or individual eyelashes, or individual sand grains ... instead of a blurry blob. It's a lot like deconvolution/deblurring results, where a blurry picture becomes in focus. For traditional workflows, you can "cheat" by using some line thinning / line enhancement filters on certain types of cartoons/animation - but that method does not work well on live action sources . For the medium quality input cases - there is usually no fine, high frequency detail in the output, but it can sometimes still be an improvement (if/when it works well), some objects or textures can be more clear than you'd get with plain sharpening - although you'd have to weigh all this against the "negatives"
The older NNEDI3_rpow2 is also a NN scaler , but it does not produce much more resolution than a traditional scaler, so the output is "coarse" as well. The original NNEDI came out ~ 2007, and all of the NNEDI the family are basically scaling with some edge antialiasing (that's what the "edge directed" in Neural Network Edge Directed Interpolation is for). It was not trained for anything else, and it's not a very "deep" network compared to some of today's networks. The weights file of some newer architectures can be 4-5x the size of NNEDI3's
Some people say these scalers are "just sharpening". It can partially be - some models have sharpening built in. But it's not only sharpening in the situations I'm referring to. That magnitude of difference can only be obtained from an actual increase in resolution. Check out the resolution test in the earlier post, no traditional sharpening can increase the resolution on a test chart - in fact, sharpening often reduces the resolution by producing halo and moire patterns at lower resolution patterns, reducing the test chart"score". You can see how clear the numbers looked in the chart with ESRGAN without halos or sharpening artifacts, and lanczos3 already had ringing and edge artifacts to begin with. If you were to sharpen the lanczos3 result, the artifacts would just get worse. There will be examples posted where it's impossible to get those results with traditional workflows - but they almost always come with potential issues
For NN scalers , there are 3 main quality / ARTIFACT issues that can arise -
1) noise enhancement (related to noise already present in the picture, such as sharpened noise artifacts) , or depending on which model you use, some oversmooth (ones that have denoising built in) - so detail loss. Over denoised and over sharpened has that ugly oil painting look - lots of videos posted like that
2) new synthesized artifacts - sometimes they look very bizarre and distubing . They can make mistakes when predicting from small details. Sometimes small artifacts, sometimes major artifacts
3) temporal artifacts - There is a flicker , sometimes aliasing, sometimes object inconsistency. A screenshot does not show these, motion problems .
Any of these 3 can potentially be deal breakers, and make them worse than traditional methods to the point of being unusable. Pros/cons. You often(always) have to search through the output for artifacts and issues, and decide how to handle them, or they will bite you in the ...
In general, there are conservative tuned PSNR based models which tend to get closer to the ground truth in PSNR dB, but the results look more blurry, less detailed. Other models are peceptually tuned, more aggressive that produce sharper results and more detailed textures, but have a higher risk of artifacts and noise. The latter ones generally score higher in subjective perception evaluations such as VMAF. It's very similar to lossy compression techniques such as PSNR tuning vs. perceptual tuned psy optimizations that x264 has. If you're risk adverse, use a more conservative model, or use traditional methods
For temporal issues - VEAI has motion compensated models - but they often produces other artifacts such as ghosting, blurring , and the upscaling isn't as good/sharp on some scenes. You can check the json and most use a 5 frame window, but there are still temporal issues in all the models in some cases. Flicker generally arises because many of the NN scalers are spatially trained on single images, and generally do not have motion compensation (few exceptions, TECOGAN, and some newer ones look at multiple frames such as 3 and 7 frame RRDB variants, SOFVSR, most VEIA models are trained on video). TECOGAN deserves special mention, because it produces very temporally consistent results. But it has less drastic wow factor in terms of details based on public models - it's quite blurry on higher resolution input videos. TECOGAN needs to be investigated more with different trained models. Blurry videos generally have fewer aliasing and flicker issues as ones that have sharp details. Or to put it another way - one approach to reduce aliasing and flicker is to blur it spatially (horizontal, vertical) and/or temporally. If you apply post processing with additional temporal filters and smooth the flicker artifacts from any of the NN scalers - you diminish the fine details which distinguished it in the first place.
A common post technique is to use QTGMC in progressive mode to smooth over the flicker and temporal inconsitencies (but again , you lose details, and it poses a risk of adding temporal artifacts). Traditional scalers have flicker problem as well - because they also work on single frames. It's more visible on larger upscales such as 4x. The NN scalers almost always have more visible temporal issues because: a) the details are more clear instead of blurred b) they generate predicted details, and that can fluctuate frame to frame as they "guess" some details. In the next post , there is a flicker demo example to illustrate one of the types of object inconsistency artifacts being talked about
It's highly unlikely the model you use was trained for your exact source. So you often have to apply other filters for post processing: maybe denoise it a bit, or sharpen it a bit. Some models are not color neutral - they alter the hue of the source slightly because of the training set (not referring to 601/709 mismatches, or mac gamma issues), so you might have to adjust color a bit.
If artifacts during upscaling are plausible, and temporally consistent, it's not necessarily detrimental for general use cases. e.g a hair strand or some vellus facial hair might be predicted to be slightly out of place. Stubble might appear at a different angle than the ground truth. As long as those are plausible, and consistent in other frames - it can be a good upscale for general use. But if the predicted artifacts jump around , move places, or look out of place , or obviously fake/weird - that can be unusable, or it needs to be addressed with other techniques such as filtering or compositing. Caution has to be taken for other uses - such as forensic or medical imaging.
There are cases where predicted artifacts can make NN scaling results almost unusable, especially when using "aggressive" models, e.g. small text, signs , known specific objects, patterns or people that you *know* what they look like exactly, but sometimes the result can be slightly off in prediction - your brain screams that something is off, and that ruins the illusion of plausible artifacts. eg. your brother has a small mole on his left cheek, but on the upscale the mole has changed shape. Eyes and teeth angles can go weird - this is quite common for Remini - it might be plausible looking like a "deep fake" to someone else but this is a known person and you know it's "off." Small text/numbers/characters are a frequent "killer." It can be some non important stuff in the background that will stand out like a sore thumb. These algorithms follow their training (if it was not on text) and and try to connect lines and angles up but you end up with alien looking text. For situations like deblurring license plates, it's generally not suitable, unless you use a model that has been trained specifically for text,fonts, and motion blur (and even then you'll never get extent of the tv/movie versions where 4 pixels become a full 8K picture legible from the next room over and around the corner)
Here is an ESRGAN example of a specific cartoon trained model that is specific for a type of art style, and line artifacts. Looks like an improvement overall for this art style, but the name plate "Smith" is messed up.
https://github.com/rlaPHOENiX/VSGAN/blob/master/examples/cmp_1.png
This is a crop of 640x360 4x upscale. View it at 100% . Small text is often messed up as the NN tries to make connections that aren't there. Yes it's more clear... but clearly wrong. A more "graceful" blur would be preferrable to the "pixels" text for most people. I'll eventually get to posting the full src input/output examples in other posts, but other parts of the video might look ok but stuff like that just sticks out. Yes, there are easy workaround for static overlays, but what happens when you have camera motion to the background text on say, a building sign, a traffic sign, a mailbox, a designer label on a jacket or hat, the sci-fi display on some starship panel or transporter controls... etc... They can sometimes get messed up too if they began small, and worse, they can flicker and change shapes. You'd have to motion track and roto it out, or combine other methods with masks to fix it. You have to double check your results.
[Attachment 56620 - Click to enlarge]
Another downside is they are a lot slower, even with GPU acceleration, and they are not as easily "tweakable" "on the fly" compared to traditional filtering applications. It's difficult to know what you're getting with the slow preview feedback ; and even if you do know - you can't really adjust much for most models. VEIA has added models and improved/retrained some of them. But it does not have options to blend models as you can with some frameworks such as ESRGAN; eg. you might want a more conservative, fewer artifacts, at the expense of less sharp, fewer fine details model. Maybe an Artemis-MQ 80%, Gaia-HQ 20% or something. For VEIA, it's theia model there are some controls, but it would be nice to be able to dial in levels like sharpness, artifacts, noise, for all the models, or be able to combine the models (ie. more options, more models, more control would be nice). Gigapixel is different in that regard, you can control some parameters like other filtering applications with sliders -
Video Restorer

- Jun 2003
- dFAQ.us/lordsmurf



I'd say this mix very lopsided. A small % works well, mostly cartoon/animation. But most do poorly, especially with sources that truly need quality upsizing. Clean source is a must -- and something like VHS or DVD is inherently noisy. Film is the real winner here. But again, it doesn't really work all that well, most times, with most sources.Originally Posted by poisondeathray
I wish this wasn't the case. We all want the magic CSI "enhance" button. Perhaps someday, but not now, probably not even in the near future (within this 2020s decade).
What really irritates me is that there are too many charlatans and cheerleaders in the NN/upscale space, willfully ignoring flaws of various uspcale methods. One has financial interests in their own BS, while the other is just blind idiots. I've seen so many terrible upscale examples in the past decade, all the way up to a few weeks ago in 2020.
Very often, the best upscale advice is to NOT do the upscale unless forced (ie, mixed source documentaries).
Hopefully this conversation stays on course with nitty-gritty scientific details, and doesn't devolve into a love orgy for Topaz or other softwares.
Thanks for doing this PD. Want my help? Ask here! (not via PM!)
Want my help? Ask here! (not via PM!)
FAQs: Best Blank Discs • Best TBCs • Best VCRs for capture • Restore VHS -
Yes, I agree. I expanded on this in the lengthy 2nd post. There are 2 clear (limited) situations where some of them can work (but you have to comb through them looking for artifacts. An artifact free run is like winning the lotto, or if you can ignore some of the smaller ones)Originally Posted by lordsmurf
Examples coming... -
56K warning!
I'm uploading lagarith RGB versions, to control the variables with RGB<=>YUV conversions, etc... (FFV1 will usually give RGB compression, but MKV and FFV1 containers have less support in NLE's, e.g someone might want to compare them as layers in an editor). I'm using short test sequences to illustrate pros/cons because of bandwith and time constraints
ladies_1080_lags_rgb.avi is the 1920x1080 HR reference version, it was bicubic dowscaled to 640x360 for the LR. No preprocessing was done on any of the examples for LR input - as it is fairly clean with just very mild sensor noise. Output from 4x models (2560x1440) are downscaled to 1920x1080. Spline36 is used for everything unless otherwise noted. The post processing for any of them used QTGMC in progressive mode in vapoursynth with sharpness at 0.5, YUV444P10 is used as the intermediate because QTGMC does not work in RGB . CAS(0.5) sharpnening is applied after. ESRGAN+ used 0.4/0.4 instead of 0.5/0.5, because it was it was sharper to begin with, it probably should have been adjusted lower. The values were mostly chosen for simplicity and ease of testing, certainly you can adjust values and get better results.
Unless there are specific requests, I probably won't upload all versions, just a few of them including the "raw" 2560x1440 NN outputs so people can play with them, maybe try some better filtering, try other scaling and sharpening methods on the LR. It's pretty easy to use "lanczos3" e.g in vdub2 or similar, so I probably won't upload those ones. Feel free to stack them, splitscreens, wipes, interleaves, etc.. to help visualization comparison. Maybe I'll add more over time
-"ladies_1080_lags_rgb.avi" is the 1920x1080 HR reference
-"ladies_360_bicubic_lags_rgb.avi" is the 640x360 LR
-Native outputs have no number preface , so e.g. "ladies_bicubic_esrgan.avi" would be the 4x direct output of esrgan default
-Post filtered versions have a "1" preface, so e.g. "1veai_gaiahq+qtgmc.avi" would be the filtered version with downscaling to 1920x1080 + QTGMC/CAS
"animated" screenshots use APNG (webp animated gets better compression, but it can have problems). Browsers like Firefox, Chrome should support it apng. 2x zoom enlargements use nearest neighbor algorithm. If they are too big for your page layout, click on them they should open up in a new window. If they don't play try downloading the attachment and opening them locally. Some browser settings might prevent them from displaying properly. I'll also include the individual png sequences in a zip.
General comments:
Conventional methods, the traditional scalers, or early gen NN scalers (NNEDI3_rpow2) produce softer results with aliasing. There is no way conventional sharpening filters can produce results as clear as deep NN scalers in this "textbook" case with clean source + clean bicubic downsample + appropriate model.
Temporal flickering and aliasing artifacts are present in all native (not farther post processed) versions around the necklace, thin earrings and hair. It's worse with NN scalers because: A) the details are more clear , so the artifacts are more clear. Those with more blurry results obscure the shimmering to an extent, but you can still see it. B) Additional shimmering is with NN scalers because some of the predicted details are not consistent. A good example is the thing earrings. The loop patterns are predicted to be slightly different orientations in different frames, producing some inconsistencies - looks like some crazy scientest's live electricity demo . There is still some mild shimmering in all of them post filtering, even a plain lanczos+qtgmc, or nnedi3_rpow2+qtgmc, I didn't have much time to play with settings but you could use inputtype=2 or stronger settings. It doesn't look too bad at real speed video in motion post filter.
. There is still some mild shimmering in all of them post filtering, even a plain lanczos+qtgmc, or nnedi3_rpow2+qtgmc, I didn't have much time to play with settings but you could use inputtype=2 or stronger settings. It doesn't look too bad at real speed video in motion post filter.
This demo was about flicker/aliasing/shimmer artifacts, but you can see the difference in the level of fine detail between lanczos and a more aggressive NN scaler. ESRGAN_psnr is a conservative tuned scaler. VEIA GAIA looks like it has some vertical bars, make a note of this for later.
Pre filtered output aliasing/shimmering @4x 2560x1440 apng

Post filter output aliasing/shimmer @1920x1080 apng

Next are horizontally cropped motion tests - stacked side by side; these are converted to 4:2:0, libx264 crf12 , so lossy, and color subsampling, but just an indication of how they look in motion side by side. ie. how bad is the shimmer/flicker, is there ghosting or other temporal artifacts introduced by the scaler, or post filtering,etc... This one is low motion and short sample, but those some of the things you want to evaluate and on other samples. Those are attached and the "stack_MP4" files. These are from the "final" 1920x1080 versions . The cropped interleaves are 4:4:4 libx264 crf12 , this method of visualization is like swapping layers on/off in a NLE for each frame. They are MP4 with "interleave" in the filename.
1440_screens.zip is a sample of screenshots from frame 45 of the native 2560x1440 outputs . 1080_screens.zip is a sample of frame 45 post filter of the 1920x1080 output
Metrics.
I don't put much weight into metrics alone, but they can be a useful aid with other information for looking at trends in combination with other information
The metrics were measured with the lossless 1920x1080 versions, using libvmaf's psnr and ssim (calcs can be slightly different between metric implementations, vmaf ssim downsamples the image, but the trends should be similar between implementations). Harmonic mean pooling is used for the aggregate scores. VMAF is the only metric has a temporal component, SSIM/PSNR measure single frames then average.
ESRGAN's PSNR tuned model scores highest in PSNR as expected. ESRGANplus' default model is aggressive and scores highest in VMAF. ESRGANplus scores higher in VMAF than ESRGAN or ESRGAN_PSNR, but lower in PSNR. This is expected because VMAF is a subjective perceptually tuned metric.
All of them benefit from post filtering according to metrics for VMAF, not surprisingly. This used VMAF 1.x, not the recently released 2.x branch. The older branch saw increases from post filtering like sharpening. There is a newer NEG (no enhancement gain) model introduced in 2.x that is supposed to compensate for things like sharpening. I may update with additional testss, but I posted a non post filtered version anyways. However, that does not take into the account if sharpening is built into the upscaler, like it is with ESRGANplus, so it might be useful to add. Post filtering smoothing over of jaggy/aliasing artifacts and flicker should have some benefit ,and you see that PSNR increases for most of them post filtering. ESRGANplus and VEAI GAIA both decrease in PSNR/SSIM/MS-SSIM after filtering. You often see this trend with perceptually tuned codecs/settings in compression tests, where VMAF goes up, but PSNR/SSIM go down.
lanczos3
aggregateVMAF="62.2507" aggregatePSNR="37.0642" aggregateSSIM="0.99551" aggregateMS_SSIM="0.987942"
lanczos3 + postfilter
aggregateVMAF="65.1621" aggregatePSNR="37.3202" aggregateSSIM="0.996014" aggregateMS_SSIM="0.988724"
nnedi3_rpow2(4, cshift="spline36resize", fwidth=1920, fheight=1080)
aggregateVMAF="62.2329" aggregatePSNR="37.0384" aggregateSSIM="0.995092" aggregateMS_SSIM="0.987449"
nnedi3_rpow2(4, cshift="spline36resize", fwidth=1920, fheight=1080) + postfilter
aggregateVMAF="65.2768" aggregatePSNR="37.3014" aggregateSSIM="0.995607" aggregateMS_SSIM="0.98825"
ESRGAN
aggregateVMAF="75.191" aggregatePSNR="38.1848" aggregateSSIM="0.996972" aggregateMS_SSIM="0.99112"
ESRGAN + postfilter
aggregateVMAF="78.9133" aggregatePSNR="38.2015" aggregateSSIM="0.997182" aggregateMS_SSIM="0.99163"
ESRGAN_plus
aggregateVMAF="86.268" aggregatePSNR="37.8696" aggregateSSIM="0.997412" aggregateMS_SSIM="0.991023"
ESRGAN_plus + postfilter
aggregateVMAF="87.8765" aggregatePSNR="37.7199" aggregateSSIM="0.997302" aggregateMS_SSIM="0.991238"
ESRGAN_psnr
aggregateVMAF="75.7766" aggregatePSNR="39.2291" aggregateSSIM="0.997712" aggregateMS_SSIM="0.992681"
ESRGAN_psnr + postfilter
aggregateVMAF="80.2677" aggregatePSNR="39.7604" aggregateSSIM="0.998016" aggregateMS_SSIM="0.993589"
VEAI GAIA HQ
aggregateVMAF="77.7872" aggregatePSNR="37.8242" aggregateSSIM="0.99671" aggregateMS_SSIM="0.98989"
VEAI GAIA HQ + postfilter
aggregateVMAF="81.1887" aggregatePSNR="37.7588" aggregateSSIM="0.996591" aggregateMS_SSIM="0.989708"
The next series are no post filtering, the immediate output at 2560x1440. (You can't really say "unfiltered", because a model can have built in denoising/sharpnen/etc..). Also note "HR_ref" is not a "true" reference in these shots, because it's upscaled to 1440 - it's just used as a rough reference. Make sure you view them at 1:1.





Another bad artifact is the girl on the right's teeth and eyes on VEAI GAIA HQ in the screenshot below, the teeth look like new cavities formed, the shape has changed, and the eyes have red splotches, and it's missing eyelashes. Eyes looks ok with ESRGAN+, but you see some elements of teeth distortion in several frames. Some teeth issues are actually there in every version, even traditional like lanczos, nnedi3_rpow2, for example frame 10 the bottom of the 2nd left tooth angles up, instead of flat. Some of the tooth issues are just enhanced and in focus now compared to the other traditional scalers. The tooth angle change is an enhancement of an already present artifact, but the bloodshot eye , or "new cavities" in VEIA are a new issue altogether.
VEAI Gaia-HQ has some additional vertical artifacts and more shimmering edge artifacts around the necklace. Both ESRGAN and VEAI have frames where some of the "beads" in the necklace become flat or cylindrical in some frames, some motion inconsistencies even after QTGMC. ESRGANPlus remain more similar to beads like the source. Conventional methods like lanczos , nnedi3_rpow2 shimmer too, but the blur helps conceal the artifacts slightly.
VEAI GAIA HQ's output has multiple problems. If you view the native unfiltered output, there is a grid like,pixellation overlay pattern if you zoom in, instead of fine details like the original. I'm referring to above and beyond what you'd expect with our 2x zoom - it's not visible in the other scalers. You can see the vertical bars in the apng shimmer demo above, and that was at 100%. There are horizontal line and grid artifacts, most noticable on the face apng around the mouth, and the eyes,teeth apng. Another thing it could be is point/nearest neighbor kernel resizing for some of their internal steps. In the hair,earrings shot there are vertical lines. Some almost look like applied dithering artifacts in the background if you look at the video. You can see a persistent horizontal discolored line artifact around the level of the left girl's mouth . There is more artifacting especially around the necklace compared to ESRGAN+ in this example, similar to lossy compression artifacts. Another possible explanation for single line artifact is if the software splits the input into several "tiles", to fit into GPU memory, and it does not overlap and pad the edges sufficiently, you can get "seams" along tiles when reassembled. But that does not explain the vertical bar artifacts , or small grid patterns - there are way too many and too close together. Downscaling and additional filtering help reduce some of the artifacts, but many are still visible at 1920x1080 even after post filtering.
This was done with GAIA HQ 1.6.1, many people claim that's the best one. I've looked at about a dozen clean scenario tests, and it's not that great. Sure, superficially it looks ok, some parts are sharper, and it has some hallmarks of a decent NN scaler - but there are some major issues with artifacts. I'll post some more examples when I get time but there are persistent themes with the grid artifacts. The missing eyelashes seem to be a theme on small inputs. There is so much variability of content and reported results, to the reality that I am seeing. Maybe if people posted more complete tests, such as sources, encodes , etc.. it could be examined and possibly retrained.
Yes, there are artifacts in all them, even conventional methods. Some might be considered minor (or not), eg. Some of the fur is slightly out of place, more random than the ref. If you're faced with such situations, you can switch to a PSNR tuned model, or use more conventional methods, or some mix. It depends on your tolerance for artifacts, but always check your outputs closely when using NN scalers.
For some reason I can't get the attachments to load..grrr . Problems with FF before, but chrome will usually upload, but they don't show up
Plan B - this folder will have the attachments (slowly uploading..)
https://www.mediafire.com/folder/wegho3xcuign5/ladies_upscaling_testsLast edited by poisondeathray; 3rd Jan 2021 at 23:31.
-
Video Restorer
- Jun 2003
- dFAQ.us/lordsmurf
-
An unofficial term that I use, to describe an artifacts unique to upsize, as borrowed from dSLR cameras, is "jiggle".
Upsize is never pixel accurate -- especially all the NN methods. What inevitably happens is that pixels do not know exactly where to go, and may offset. That sounds fine, until you remember that video is temporal/motion. Not a still photo. Very often, frame to frame, that source pixel is rendered in a different location as a destination pixel. So things move that should not move. Add in motion like panning, and the picture looks "alive" -- often in a weird unnatural Salvador Dalí type of way. The fake nature of the upsize is noticed, ugly, and distracting.
Topaz software has some of the worst "jiggile artifacts" that I've seen to date. The DS9 samples, that somebody was all proud of, was probably the worst of the worst.
nnedi_rpow2 is minimalist in this regard, but not 100% immune.
The NN guestimations are more guess than anything else.
Jiggle artifacts are as insidious as chroma noise on VHS tape, or mosquito noise from a bad MPEG/DVD encoder. It's motion that should not exist.
You're making some good posts here, wealth of info, I need to sit down and digest it all.
Want my help? Ask here! (not via PM!)
FAQs: Best Blank Discs • Best TBCs • Best VCRs for capture • Restore VHS -
Some of them, but there are fairly large discrepancies and quality differences between different versions.Originally Posted by lordsmurf
There were dozens of different versions posted on various websites - and some were obviously terribly produced - but some went through the meat grinder with buckets of pre and post work - those actually look good with minimal artifacts -
This next one has more grain/noise in the HR reference to begin
test4_HR.avi is the reference
test4_LR.avi is downscaled 4x with spline36

Same deal with flickering hair, all resizers have it, even lanczos, nnedi3_rpow2, but newer NN scalers have it worse for the 2 main reasons mentioned in earlier post. And when you do a 4x upscale, you're always going to get some aliasing and flickering on some textures
Same treatment with QTGMC inputtype=1 to reduce flicker + CAS, it also has desireable side effect of denoising in this case. Sharpness 0.2/0.4 this time for simplicity
ESRGAN's immediate output has enhanced downscaled noise/grain, looks pinpoint and smaller that the source grain.
ESRGAN_psnr output is more clean, noise is similar to nnedi3_rpow2, but it is more clear features, less hair aliasing
Iris pattern changes frame to frame on VEAI, ESRGAN outputs, as they make slightly different predictions each frame. Partial explanation, because nnedi3_rpow2, lanczos have it too, just blurred. You might not notice it in normal playback speed, but it's a pretty cool psychadelic sci-fi effect in it's own right, like some swirling liquid pool of iris... but not wanted for the purpose of this test. It can be stabilized with QTGMC
gaia-hq has temporal 5 frame according to the json, but hair still flickers and iris pattern still swirls. It's immediate output is cleaner than esrgan's . But there is severe ringing around iris, has more unnatural look with overdenoise/oversharpen after QTGMC smoothing, but overall looks more clear than lanczos or nnedi3_rpow2. If the hair didn't have the flicker, you wouldn't need QTGMC, and it would look better. Or apply filter through roto/mask only on hair . No eyelashes again ; on both lower eyelids this time on most frames
lanczos has aliasing jaggies in hair that flicker. Fuzzy soft look, but noise/grain background is blurred
nnedi3_rpow2 similar to lanczos but less jaggies in the hair (it's basically resizing with antialiasing). Same fuzzy soft look as lanczos
files folder link
https://www.mediafire.com/folder/6v2px9ff98ikz/tos_test4_upscaling -
Video Restorer
- Jun 2003
- dFAQ.us/lordsmurf
-
This conversation merits more discussion.
It saddens me when good topics like this are buried in favor of "help me download Youboob video, k, thnx"Want my help? Ask here! (not via PM!)
FAQs: Best Blank Discs • Best TBCs • Best VCRs for capture • Restore VHS
 Quote
QuoteSimilar Threads
-
so where's all the Topaz Video Enhance AI discussion?
By brandon87 in forum Video ConversionReplies: 575Last Post: 19th Jul 2023, 05:37 -
Pioneer DVR-520 and DVR-560 functionality discussion
By jcool in forum DVD & Blu-ray RecordersReplies: 142Last Post: 17th Aug 2021, 19:45 -
general question about chroma cleaning
By Betelman in forum RestorationReplies: 7Last Post: 6th Jun 2020, 11:38 -
Is the general public's expectation of video quality going down?
By lingyi in forum Newbie / General discussionsReplies: 22Last Post: 18th Dec 2019, 00:54 -
How to find the link of video to download in general
By bfa1trung in forum Video Streaming DownloadingReplies: 2Last Post: 4th Dec 2019, 14:10