




1) no, the apps will not need to be rewritten and/or optimized, this isn't a new SIMD set nor is it an intel specific api, i'm talking about this:Originally Posted by poisondeathray
http://www.xbitlabs.com/news/video/display/20091204232215_Intel_s_Next_Generation_Plat...ort_GPGPU.html
note the part where it says the feature will be available via a driver update. a driver, by definition, is a piece of software that tells the OS how to use a particular piece of hardware, if the video encoding is to be introduced via a driver update then more than likely what will take place is that calculations associated with video encoding will be offloaded to the gpu for faster processing.According to an Intel's spokesman, its next-generation code-named Clarkdale central processing unit with integrated graphics core will support video encoding using graphics processing engines via a driver update. Despite lack of initial support of the feature, which will be added using a driver update, there is a confidence in the forthcoming Intel’s integrated desktop platform.
this type of acceleration doesn't require that an app be rewritten, the driver can have a built in run-time compiler to distribute instructions accordingly, nvidia used to have such a run time compiler bundled with it's drivers back in the 5800 fx days, if you recall nvidia was accused of "cheating" during benchmarks because it would check to see what apps were running and actively intercept 32 bit math calculations and replace them with lower precision 24 bit calculations and the apps were none the wiser.
intel can easily do the same thing, simply have the driver include a run time compiler, when it detects a single or double precision x87 instruction or 128 bit sse floating point instruction, allow the instruction to be fetched and decoded as normal, then pass the rest to the gpu for faster calculation and return the results to the cpu for execution and retirement.
we're not talking rocket science here, it requires no rewriting of apps, no optimization, nothing on the part of the developer, now it's true a developer aware of this process could further optimize the app so as to streamline the process but that would just be for further speed refinement.
the only question is whether intel will actually allow the driver programmers to exploit the potential.
+ Reply to Thread
Results 31 to 60 of 80
-
-
Please re-read what was written. I said there will be some native benefit, but in order to fully take advantage of the on die GPU, the instructions have to be re-written
If you look at the leaked benchmarks on Taiwanese and HK websites, the clarkdale is faster than current dual cores, but slower than a quad core for h.264 encoding - which is what I said. In theory it's still underperforming for what it was projected to be doing. Why? Because the software hasn't been optimized to use those types of calculations yet.
A GPU (whether on die or off die) is still limited to certain types of calculations and cannot handle everything that a CPU can. The way current encoders are programmed cannot make use of GPU's to the full extent.
In order to maximize the theoretical advantages , you need to re-write the applications, that's all my point was -
Thanks go to everyone for the outstanding input. Much appreciated.

-
i've seen the benchmarks, i have been following the clarkdale very closely, the reason the clarkdale is currently slower than current quad cores for h264 encoding has zero to do with the software not being optimized it's because the gpu acceleration driver hasn't been released yet, it's not available anywhere, it's not part of any driver currently available, so i would expect a dual core cpu to under-perform compared to a quad core under a well threaded encoding app.Originally Posted by poisondeathray
revisit the same tests once the driver is released, you can think of it as a shot of nitrous oxide, once that driver hits the general public no quad core will be able to beat a clarkdale under any encoding scenario, hell i think the 6 core 12 thread core i9 will have a tough time keeping up.
of course i could be proven wrong, intel may seriously screw up the driver, they may be afraid of cannibalizing sales of their quad core cpu's, we'll know in about 2 months, book mark this thread, by feb or march of 2010 clarkdale and the driver will have been thoroughly tested and i will be proven either right or wrong.
now if you'll excuse me there's a bunch of hard core hi def porn that isn't going to download itself... -
I hope you're right... but you're going to be proven wrong, at least for x264 encoding. You can ask the developers about the intracies of how this won't improve x264 encoding much. Even simple math would suggest you are wrong. A quad core is about 2x faster than a dual core of the same generation. Do you think offloading or accelerating the floating point calcs (or GPU specific calcs) only would cause a greater than 2x fps increase to make up for that? Even if the floating point calcs are done faster, you still have the CPU bottleneck (the CPU specific calculations still have to be done by... guess what... the CPU.). Now you are suggesting a >3x increase (ie. 300%) since you think it will beat an equivalently clocked hexcore i7.....I seriously doubt it.Originally Posted by deadrats
BTW , the 32nm hexacore is not called i9, it's officially called i7 980X
Apologies to Engineering for the thread hijack... -
That just means it supports the hardware encoder hooks of DirectCompute in the upcoming DX 11. Only programs that use that DX feature will get hardware encoding. Just like with hardware decoding via DXVA where programs that don't support DXVA don't benefit from hardware decoding.its next-generation code-named Clarkdale central processing unit with integrated graphics core will support video encoding using graphics procesising engines via a driver update.
http://en.wikipedia.org/wiki/DirectCompute
And, I forgot to mention, as with all things video related at Intel, the implementation will be poor. Both in performance and quality. -
rallynavvie, thanks for the idea of using the SSD for a PS scratch drive. Hadn't thought of that.
 I'm not really using it for much anyhow because of it's small size. I have three 500GB WD black drives on the PC.
I'm not really using it for much anyhow because of it's small size. I have three 500GB WD black drives on the PC.
-
sorry, but you are wrong. dx compute is part of dx 11, the integrated gpu on the clarkdale is a dx 10 part, thus there is no "hook", the only way that gpu acceleration is going to be implemented via a driver update on the clarkdale is in the manner i have described. think of it as practice for sandy bridge, eventually the hybrid fp/sse unit on cpu's will be eliminated as all floating point math will be handled by the integrated (into the cpu itself) gpu.Originally Posted by jagabo
as i said, let's wait 2 months or so, we can then revisit this thread... -
Yes, and how is larabee doing?Originally Posted by jagabo Where is that thread where mr. deadrats made similar predictions about how good larabee would be?
Only teasing
-
Yes, killing Larrabee was an admission by Intel that they were hopelessly behind Nvidia and ATI in video.
-
By all means, I encourage it! We're all learning a good deal sitting back and reading the input of all these seasoned intellects - we're lucky to have you guys at the forums....keep at it. Happy I started it lolOriginally Posted by poisondeathray
-
1) you place way to much stock in the developer's of x264 have to say. i have read though quite a few of their blogs and at times i am surprised that they actually managed to code anything much less a codec. i remember reading through one of their threads where they were "explaining" why they didn't port x264 over to cuda and the explanation they gave proved to me that these guys aren't the greatest programmers in the world, here's what they said:Originally Posted by poisondeathray
in a nutshell they said that x264 scales linearly to 16 threads (which i doubt is true) and the code as it stands now doesn't scale past that. cuda applications on the other hand, according to them, don't show any speed advantage until they get to 128 threads and above.
this explanation is idiotic beyond belief, these guys are out of their minds if they think that any programmer can code an app to launch more than 128 threads AND manage to keep track of all the threads to prevent locks and stalls. hell the top of the line gpu's can keep 30+ thousand threads in flight, do these guys actually believe that any programmer on the face of the earth is capable of writing code that can launch and manage that many threads? it's a laughable notion and one that tells me that these guys aren't the most hardware savvy bunch to ever walk the earth.
the fact remains that gpu's have hardware that automatically takes care of threading, all a developer has to do is worry about coding the app, the threading is handled in hardware. that's one of the reasons that so few games and apps can use dual gpu cards, i have a 9600 gso, which is dual gpu, and i know for a fact that all current cuda apps only make use of 1 gpu, they don't scale across 2, if gpu programmers were really capable of coding the apps to launch thousands of threads then adding a second gpu wouldn't stop them, but it does.
ergo the x264 developer's reasoning shows a fundamental lack of understanding as far as hardware thread dispatching is concerned, but what do you really expect from a bunch of guys that can't even code a codec that can handle interlaced content properly. i mean for the love of God, even wmv and xvid developers know how to handle interlaced content, what the f*ck is the x264 developer's major malfunction?
to address your concerns about cpu bottlenecks, the floating point ability of modern cpu's is the major bottleneck, just compare the performance of any modern cpu, quad core, when doing x87 math and when doing ssefp math, which is floating point math done using sse instructions, the difference between fp operations and ssefp is easily a factor of 4 (try it with something like tmpg express, disable all the optimizations and just use floating point and then rerun the same test with the highest sse your cpu supports) and the 4x speed increasing in floating point calculations don't flood the cpu creating a bottleneck in another area.
furthermore cuda acceleration already gives a perfect chance to test the increased floating point performance and we don't see the cpu becoming a bottleneck.
lastly consider this, a i7 920 is capable 60.22 gigaflops when using sse3 (which is way, way faster than x87 flops), a 9500 gt, a rather low end gpu, is capable of 88 gigaflops:
http://www.pcstats.com/articleview.cfm?articleid=2459&page=6
http://www.pcgameshardware.com/aid,657567/Geforce-9400-GT-reviewed/Reviews/
at 60.22 gigaflops for a quad core, a hexa-core nehelam based cpu is projected to be capable of about 91 giga flops using sse3 instructions, as a general rule of thumb x87 is about 4 times slower, the question you need to ask yourself is this: do you really think that the integrated gpu on the clarkdale will be slower than a 9500 gt? even if it's only just as fast, that means a gpu accelerated clarkdale that costs under $150 can give a $1000 plus (and you can be sure it will be way plus) hexa-core a serious run for it's money.
no matter which way you look at it it behooves everyone to wait until clarkdale and the driver have been thoroughly tested before sinking any money into a new build. -
i believe i may have also mentioned that larrabee was most likely a test run of sorts, intel already has supplied 48 core cpu's to various researchers around the country at various universities, but i have repeatedly said i don't think we'll ever see, nor should we, more than 4-6 cores on the desktop. we don't need 48, 80, 100 core cpus where each core can only keep a single thread in flight at a time, even a hyper threaded 100 core cpu would only be able to handle 200 threads at a time, gpu's already on the market can keep 30 thousand threads in flight at a time, just integrate the gpu into a single cpu core and you're done.Originally Posted by poisondeathray
and that's exactly the direction intel and amd are both heading. -
That writing has been on the wall for years. Except there will still be a use for multiple x86 cores.Originally Posted by deadrats
-
Perhaps you misread or selectively read what is going on. Some of algorithms used by x264 cannot be parallelized, or have to be re-written such that the can take better advantage. e.g. CABAC, motion estimation etc... Simple as that. Even a non programmer like me understands this. Cuda "cores" are discrete units which are only capable of certain types of calculations. The rest have to be performed by CPU. There is no speed gain to using cuda, unless you have a lot of cores active.Originally Posted by deadrats
x264 can handle interlaced content fine, and it works. I've made several blu-rays that were interlaced with x264. Just because priority hasn't been assigned to developing it , and it's not as efficient as it could be doesn't mean they don't know how to improve it. I think that is an overexaggeration on your part
Since everything is "simple" to you perhaps you should join the x264 project? Maybe they could benefit from your "expertise".
This was the point I was trying to make. Even if you help the floating point math calcs, you will still have other bottlenecks. = you won't get 300% increase like you seem to suggest. Your claims are ludicrous. Now if the software was re-written to optimize for this, there might be another story.to address your concerns about cpu bottlenecks, the floating point ability of modern cpu's is the major bottleneck, just compare the performance of any modern cpu, quad core, when doing x87 math and when doing ssefp math, which is floating point math done using sse instructions, the difference between fp operations and ssefp is easily a factor of 4 (try it with something like tmpg express, disable all the optimizations and just use floating point and then rerun the same test with the highest sse your cpu supports) and the 4x speed increasing in floating point calculations don't flood the cpu creating a bottleneck in another area.
You sounded semi intelligent until you started to use "gigaflops" as a measuring tool. You might want to do some more background reading on what a gigaflop is , how its measured, what it really means and how it applies to real life situations.lastly consider this, a i7 920 is capable 60.22 gigaflops when using sse3 (which is way, way faster than x87 flops), a 9500 gt, a rather low end gpu, is capable of 88 gigaflops:
http://www.pcstats.com/articleview.cfm?articleid=2459&page=6
http://www.pcgameshardware.com/aid,657567/Geforce-9400-GT-reviewed/Reviews/
at 60.22 gigaflops for a quad core, a hexa-core nehelam based cpu is projected to be capable of about 91 giga flops using sse3 instructions, as a general rule of thumb x87 is about 4 times slower, the question you need to ask yourself is this: do you really think that the integrated gpu on the clarkdale will be slower than a 9500 gt? even if it's only just as fast, that means a gpu accelerated clarkdale that costs under $150 can give a $1000 plus (and you can be sure it will be way plus) hexa-core a serious run for it's money.
no matter which way you look at it it behooves everyone to wait until clarkdale and the driver have been thoroughly tested before sinking any money into a new build.
I agree it wouldn't hurt for those building in the next few months to wait for tests. But there are other tasks that CPU's do better, and multiple CPU cores would perform better on
Yes, the integrated GPU is slower than a 9500GT for 3D graphics tasks like games. Hell it's even slower than a 9400IGP . The ~10% increase in overall performace over current dual cores is primarily due to hyperthreading. But for 3D and graphics,do you really think that the integrated gpu on the clarkdale will be slower than a 9500 gt?
-
no, you think you understand it, just like you think you understand cuda cores. there is no question that you are quite knowledgeable and experienced with video encoding in general but your lack of programming background and lack of formal study in regards to computer architectures comes through at times, such as now.Originally Posted by poisondeathray
i know what i read, i know what they posted, it was in that "diary of an x264 developer" blog, tomorrow i am going to go through the whole thing and see if it's still there.
you also need to stop thinking about "cuda" cores, this has nothing to do with cuda, all it has to do with is the ability of a gpu to perform floating point math faster, by a significant margin, than a cpu can, that is all.
everything else is just distracting and obfuscating the issue.
you seem to be madly in love with x264, why is that? do you happen to know the developer's personally. regardless, you yourself have told me that x264 is very poor when it comes to interlaced content and you have advised me not to use it for my interlaced dvd's, why the 180 now?Originally Posted by poisondeathray
you're really having trouble today following what i have said, i don't know how i can explain it any easier. you seem to be stuck on software optimizations, cuda, cuda cores, parallelism and a number of other topics that have zero to do with the subject at hand.Originally Posted by poisondeathray
i'll make this as simple as i possibly can: imagine if you eliminated the fp/sse hybrid unit currently found on cpu's with a 2 times faster floating point unit from another source, would you still think that the software needs to be recoded, optimized or anything of the sort? can you see why such a move would result in across the board speed boosts. well that's all that happening with the integrated gpu on clarkdale: instead of using the fp/sse unit for floating point math it will use the gpu, that's it, all your other objections are null and void, they don't come into play.
only "semi" intellegent? (<yes, i misspelled it on purpose). a flop, which is what we have been talking about, is a FLoating point OPeration per unit time (in our case, a second), a giga denotes a billion, thus a giga flop would be a billion floating point math operations per second.Originally Posted by poisondeathray
ergo a cpu that can perform more flops would have greater performance, in the case of many types of video encoding that rely heavily on floating point math, the greater the number of flops it can handle, the greater the performance.
it should be noted that all types of optimizations, including threading, ultimately boil down to allowing a cpu to perform more integer and floating point calculations, thus it makes sense to focus on improving those fundamental functions rather than improving the round about way cpu manufactures have been using to improve said performance, like more cores, larger caches, improved schedulers, better threading and so on.
you can be very obtuse (thank you shawshank redemption for that word) when you want to be, are you aware of that character flaw?Originally Posted by poisondeathray
you are quoting the 3d performance of a cpu/gpu combo that hasn't been released yet, using beta hardware and drivers, that uses shared system memory, and concluding that it's slower than a 9500 gt, that is a discrete solution, with well baked drivers and it's own on board ram, which can be either 512 or 1024 mb of dedicated ram. really?!? that's the stance you wish to stick with?
how about you extrapolate what final bios' and drivers, and some additional ram would do for performance.
and for the, what is it now, 3rd, 4th time, the video transcoding driver isn't available just yet, there are no benchmarks, calm down, once it is released and proper benchmarks can be made, then we can see how right i am, until then we'll just have to wait. -
Fair enough, I never claim to be a programmer. I bow to your infinite knowlegeOriginally Posted by deadrats and I'm here to learn. Please enlighten.
I mentioned cuda cores because YOU brought it up when discussing integration of x264 with cuda. If you want to stick with clarkdale , then quit confusing the subject!you also need to stop thinking about "cuda" cores, this has nothing to do with cuda, all it has to do with is the ability of a gpu to perform floating point math faster, by a significant margin, than a cpu can, that is all.
I've already explained why. It works fine, but the huge encoding efficiency advantage is reduced because interlaced encoding hasn't been a priority for development. Your early statement suggested that it did not work at all, or could not handle it.you seem to be madly in love with x264, why is that? do you happen to know the developer's personally. regardless, you yourself have told me that x264 is very poor when it comes to interlaced content and you have advised me not to use it for my interlaced dvd's, why the 180 now?
Why can't you understand this simple concept? Even a non programmer such as myself understands this.you're really having trouble today following what i have said, i don't know how i can explain it any easier. you seem to be stuck on software optimizations, cuda, cuda cores, parallelism and a number of other topics that have zero to do with the subject at hand.
i'll make this as simple as i possibly can: imagine if you eliminated the fp/sse hybrid unit currently found on cpu's with a 2 times faster floating point unit from another source, would you still think that the software needs to be recoded, optimized or anything of the sort? can you see why such a move would result in across the board speed boosts. well that's all that happening with the integrated gpu on clarkdale: instead of using the fp/sse unit for floating point math it will use the gpu, that's it, all your other objections are null and void, they don't come into play.
I never said it would be slower. I said it would be faster and is already benchmarked to be faster than current dual cores. If everything works as planned it should even be faster once launched. However, I said it needs to be optimized to realize the full theoretical advantages.
Do you understand what a bottleneck is? Do you think all encoding calculations can be done by or accelerated by the GPU? Wouldn't it be called a "CPU" if it could do all calculations?
Great, I never said it wouldn't improve performance. But if most of the calcuations involved ("not many types of..") cannot be calculated by the GPU, or there is a bottleneck, your actual performance is lower than you theoretical. This is a very simple concept, and I didn't need to take a class in computers to understand thatergo a cpu that can perform more flops would have greater performance, in the case of many types of video encoding that rely heavily on floating point math, the greater the number of flops it can handle, the greater the performance.
At the code level if you could move more of these calculations to take advantage of off die integer and floating point calculations, wouldn't it run faster? (in the absense of other bottlenecks) ? Are you saying it this doesn't matter? Because this is what I mean by optimizations. It doesn't need to be optimized, it just would be faster with them.it should be noted that all types of optimizations, including threading, ultimately boil down to allowing a cpu to perform more integer and floating point calculations, thus it makes sense to focus on improving those fundamental functions rather than improving the round about way cpu manufactures have been using to improve said performance, like more cores, larger caches, improved schedulers, better threading and so on.
So let me get this straight: You're making some bold claims about 300% increased performance on an unreleased part, with unreleased drivers, that we don't know even work ? And yet you're complaining that I posted some real benchmarks on real silicon? At least we have a rough idea of how "powerful" the on die GPU is - and it isn't pretty - Intels IGP's were never "pretty." And somehow this miraculously is supposed to accelerate the calculations to do the equivalent work of 4 more physical hyperthreaded cores?you are quoting the 3d performance of a cpu/gpu combo that hasn't been released yet, using beta hardware and drivers, that uses shared system memory, and concluding that it's slower than a 9500 gt, that is a discrete solution, with well baked drivers and it's own on board ram, which can be either 512 or 1024 mb of dedicated ram. really?!? that's the stance you wish to stick with?
how about you extrapolate what final bios' and drivers, and some additional ram would do for performance.
There is no question that preliminary benchmarks can only improve with final drivers, but at least it gives us a rough estimation now of 3D performance on real silicon. What would your guess be? Do you think a 100% increase in performance with just driver tweaks for 3D performance
Great, I hope it's fast and improves performance. But faster than a hexcore using current non optimized software? Come on....and for the, what is it now, 3rd, 4th time, the video transcoding driver isn't available just yet, there are no benchmarks, calm down, once it is released and proper benchmarks can be made, then we can see how right i am, until then we'll just have to wait.
Let's discuss this from another angle. From and economics and marketing perspective. Do you think Intel would cannibalize their own sales? All tech companies position their products in tiers to cover all market niches and price them accordingly. Do you think - even for a second - that this "mainstream" part will outperform what Intel has positioned as their high end (or even extreme high end and server parts for their hexcore)?
Cheers -
on the contrary, you brought up cuda first, as an example of gpu acceleration that's not quite there yet, and used it as a way to discount intel's planned gpu acceleration. go back a few posts and reread to see who mentions it first.Originally Posted by poisondeathray
btw, would you like to know why cuda h264 encoding isn't up to par? it's because it was never meant to be. nvidia created a "skeleton" gpu accelerated h264 encoder as a sample for programmers to use as a template, as a starting point for more complete h264 encoders, basically nvidia was hoping developers like the main concept people and the x264 developers would look through the gpu accelerated code and understand how they could port their own encoders to run on a gpu. unfortunately what happened is that lazy and/or inexperienced programmers simply took the bare bones nvidia encoder and included it in their software, all they do is pass a few parameters to the skeleton encoder and call it a day.
as such don't be so down on gpu acceleration, the technology is sound, the various developers have been too lazy to take advantage of it.
dude, in the other thread on cleaning up noisy video you explicitly say that x264 sucks for interlaced content and advise me to use main concept's h254 instead, do you remember making those comments?Originally Posted by poisondeathray
first things first, just because it's called a "graphics processing unit" doesn't mean that the moniker applies any longer. since the advent of the geforce 3 gpu's have been fully programmable, once the fixed function units were abandoned in favor of shaders, the more accurate terms for a gpu would be "general processing unit", i have actually seen gpu accelerated audio encoding, specifically LAME and folding@home (i believe SETI as well) has been gpu accelerated since before cuda was released.Originally Posted by poisondeathray
allow me to make this clear, cuda did not bring gpgpu to gpu, all it did was make it more accessible, that's it.
as for a gpu being able to do "all calculations" there are only 2 types of calculations a cpu does, integer and floating point, a gpu is capable of doing those same calculations, only much, much faster. that's why the gpu by the end of 2010 (or whenever sandy bridge finally hits retail) will be melded into the cpu itself into one single processor.
as for optimizations, the reality is that none of the currently available software is in any way properly optimized, today's programmers are not the same as those from years gone by. in the old days, thanks to limited resources, it was quite common for a programmer to "get his hands dirty" optimizing his code with assembler, in order to make his program smaller and faster. back when people were coding in pascal and even the old C programmers, it was common practice to use inline assembler within a program to streamline a process and it was also common to code heavy floating point portions of a program in fortran and then call that program from within your main program, you just don't see that kind of hand optimized code anymore.
now everything is an object, code is bloated and poorly thought out and the attitude of most programmers is if the end user wants faster performance let him buy faster hardware.
hell i remember having a heated exchange with this guy that was deep into a comp sci program that didn't believe that a program written in assembler would be any faster than a program coded in C, i finally convinced him to try it out for himself so he picked up a book on assembler, studied it for a while and then wrote a small app in C and the rewrote parts of it using inline assembler and he was shocked to discover that the inline assembler program was much faster.
for the love of God, as i pointed out above, there are only 2 types of calculations a processor does, either an integer or a floating point, the limiting factor is the programmer and whether or not he knows how to code the problem.Originally Posted by poisondeathray
consider this: assume you have a processor that is only capable of ADD and MULTI, thus it can only add or multiply, can you write code to run on that processor that carries out a division? of course you can, as long as the programmer understands enough math to realize that multiplying by a decimal point is the equivalent of dividing, he can code his app accordingly. even more important, if the programmer of the compiler is savvy enough to understand this he can make the process transparent to the programmer by coding the parser so that when it runs across something like 1/2 it replaces it with 1 x .05 and sends that to the compiler instead.
here's the thing, assuming the hardware is properly designed AND the driver is properly coded, then this will be done transparently and the program will be unaware of what's actually going on and the programmer won't have to worry about that. if we have to rely on the programmer to be competent enough to manually code his app so that it deliberately instructs the cpu to offload the integer and floating point calculations, we are screwed big time, this gpu acceleration will be a massive failure.Originally Posted by poisondeathray
i'm counting on intel actually knowing what they are doing and properly coding the driver with perhaps a run time compiler so that when it sees an integer or floating point operation it actively instructs the thread dispatcher to send said instructions to the gpu and then retrieves the output. if such is the case, then there will be no way to optimize anything and in fact if the programmer tries to intervene he might crash the driver, corrupt the data or at the very least negatively impact performance.
just thinking about the possibility of a programmer trying to interfere with this process has given me chills, i can already see the BSOD's...
it should be noted that everything i have said so far is dependent on the following:
1) that the integrated gpu on the clarkdale is indeed a dx10 part as is being reported and not a dx 11 part, dx 10 parts don't support dx compute and thus the gpu acceleration wouldn't rely on the windows api nor would apps have to be coded to take advantage of it.
2) that the gpu accelerated encoding isn't dependent on open cl, though this would open the doors for extreme performance because then it could be extended to a discrete gpu for even more acceleration, the down side being that apps would need to be recoded.
3) that when that intel spokesman said a "driver" update he actually knew what he was talking about, if in fact it's a gpu driver that enables this functionality then the only way for it to work is as i have outlined, the driver will have to actively intercept calculations that would normally be carried out by the cpu and offload them to the gpu, this scenario would be ideal because it would work with all apps without the need for anyone to recode anything.
before you LOL consider this: 3d graphics are extremely math intensive as is video playback, take the most powerful cpu currently available, sans any 3d acceleration, and try to render a 3d graphics scene on it (i.e. use the software rasterizer to render in software), similarly try to playback a high bit rate h264 or vc-1 1080p video or try to play back 2 hi def video streams, even the most burly of dual socket nehelam based system would be brought down to it's knees begging for mercy. hell, try playing a blu-ray on a system without gpu acceleration, you'll be dropping frames and have jerky playback left and right.Originally Posted by poisondeathray
now take a lowly dual core amd cpu with an on board gpu and rerun the 3d tests or the video playback tests and what happens? smooth performance, acceptable frames rates.
encoding is even more math intensive than that, that's why i expect to see a dual core clarkdale smoke most cpu's except for maybe hexa-core 12 thread beasts under video encoding scenarios.
3d performance compared to software rendering performance? you're talking closer to 1000% faster.Originally Posted by poisondeathray
i actually talked about this earlier in this thread and in another thread: at first glance it seems absurd that intel would do such a thing because as you state it would cannibalize sales from it's other products, but here's a few things to consider:Originally Posted by poisondeathray
1) intel is currently engaged in a rather public and bitter rivalry with nvidia. intel blocked nvidia from producing chipsets for any cpu that has an integrated memory controller and nvidia has effectively abandoned the desktop chipset market and nvidia's president has made several harsh comments about intel not to mention the website nvidia has created just to mock intel.
2) nvidia has also stated that for all intents and purposes they are putting the desktop gaming market on the back burner and concentrating primarily on the hpc and general computing markets, with the biggest marketing emphasis of the upcoming fermi card being it's superior gpgpu capabilities.
3) i have gone on record as stating that i don't believe that nvidia will survive for another 3 years, i see them going the way of 3d fx and i think nvidia wishes to push them over the edge just like they did to 3d fx years ago.
4) intel has done things in the past that cannibalized sales from a group of processors just to gain an advantage over a competitor. consider that there are still core 2 quads on the market, intel still produces low power core 2 quads yet they also sell the much faster i5 750, in the $150 price point (give or take $10) you have the q8400, the q9550 and the i5 750, similarly in the $150 price point you have motherboards that support socket 775, socket 1156 and socket 1366, and they had no problem releasing the i7 860 at the $220 price point and it's just as fast as the i7 940 which costs $500.
intel has no problem releasing a new processor that just as fast, if not faster, than a predecessor, at a significantly lower price point.
edit: i just ran across this, the FTC is suing intel over the cpu/gpu integration that is coming:
http://anandtech.com/cpuchipsets/showdoc.aspx?i=3690
why do i get the sinking feeling that the video transcoding driver may never be released? -
Good points, and nice descriptions deadrats. Thanks for taking the time to explain it

I'm not a programmer or circuits designer, but I know you can't just port all the calculations to the "GPU". There were technical explanations of why it doesn't work for cuda specifically and x264 (sorry to drag cuda back in), but I haven't read any technical explanations or limitations of how this would apply to the integrated GPU architecture. Presumably no one knows yet or has a SDK to test to verify. Maybe you've seen some whitepapers?
(if you want to read the some of the cuda and x264 dialog, start reading from post 192 or so, they go on to make some predictions, but nothing concrete) http://forum.doom9.org/showthread.php?p=1353022#post1353022
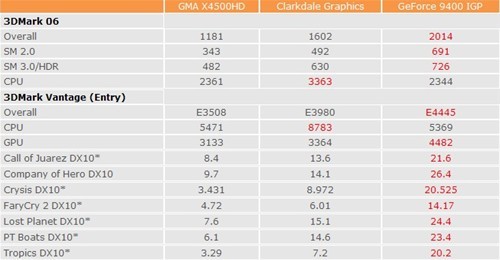
I still feel the GPU of clarkdale is too weak. Maybe a few generations from now it will make a bigger difference, not this year. If you look at those prelim 3dMark scores, it's barely better than the current integrated chips, even the low end 9500GT or GT220 score roughly 3x better.
But I suspect driver snags, less than perfect scaling (there has to be some latency losses between the interconnects), and I still think it will be slower than an equivalently clocked i7 quad with current software like x264. I guess we will find out if a few months.
Yes it does suck relatively speaking, but if you scroll up your comments suggested it didn't work at all. I'm just clarifying that interlaced encoding works using x264. It's still better than MPEG2 or xvid on most sources and under most conditions, but by a lot smaller margin than if it was a progressive source. i.e. a few % gain might not be worth the hassle, since MPEG2 encodes faster.dude, in the other thread on cleaning up noisy video you explicitly say that x264 sucks for interlaced content and advise me to use main concept's h254 instead, do you remember making those comments?
Cheers
EDIT:
OK, make that maybe longer than a few months ....edit: i just ran across this, the FTC is suing intel over the cpu/gpu integration that is coming:
http://anandtech.com/cpuchipsets/showdoc.aspx?i=3690
why do i get the sinking feeling that the video transcoding driver may never be released? -
The FTC is spot-on in it's claims. But Intel knows it can drag this out for 5 to 10 years. By then there will probably be a Republican in the White House and all new, business friendly, appointees at the FTC who will drop the suit. At worst, they'll just be given a little slap on the wrist. Without the threat of fines and punitive damages Intel has nothing to lose by continuing with integrated CPU/GPU designs.Originally Posted by deadrats
-
i already told you what the "technical" explanation the x264 developers gave was: x264 only scales to 16 threads and cuda needs at least 128 threads to really shine, which as i pointed out is completely idiotic. i've been been trying to find the thread in their diary were they talk about it, i've been too lazy to read through all the archives but now i am resolved to do it so that you can see that half-assed explanation for yourself.Originally Posted by poisondeathray
i agree, it is weak but then again it's not meant to be a gaming gpu, it's meant to be a first step towards the melting of the cpu and gpu into one cohesive unit.Originally Posted by poisondeathray -
i would hardly call all the claims "spot-on", while they do have a valid point on most of the complaints, some are just flat out ridiculous, such as:Originally Posted by jagabo
Intel “created several interoperability problems” with discrete CPUs, specifically to attack GPGPU functionality.
what interoperability problems? if anything intel has improved interoperability by moving the pci-e controller onto the die itself.
In bundling CPUs with IGP chipsets, Intel is selling them at below-cost to drive out competition
is the FTC kidding? have they taken a look at amd's pricing structure? amd quad cores retail for about $90, how much do they think amd is selling them to the distributors for? how much do they think amd makes off each one?
Intel has attempted to harm GPGPU functionality by developing Larrabee. This includes lying about the state of Larrabee hardware and software, and making disparaging remarks about non-Intel development tools.
how does the FTC figure? if anything larrabee would have increased interest in gpgpu functionality and as for "disparaging" remarks have they been listening to the nvidia president's remarks over the past 2 years? hell, nvidia has a website dedicated to posting satirical cartoons mocking intel, who's disparaging who here?
and this one just makes me want to slap someone:
Intel reworked their compiler to put AMD CPUs at a disadvantage. For a time Intel’s compiler would not enable SSE/SSE2 codepaths on non-Intel CPUs
here's a news flash: it's an intel compiler, developed by intel to draw the maximum performance from intel cpu's. the intel compiler is rarely to never used by any developer of any mainstream app, windows apps are generally developed using microsoft's visual C, sometimes using gcc and linux/unix apps are compiled using gcc. yes there was a time when the intel compiler wouldn't enable sse/sse2 code paths on amd cpu's but that was back before the athlons supported sse, so it's a moot point anyway, and again it matters not since no developer of any commercial app that i am aware of uses intel compiler. if amd wants a compiler to take advantage of it's cpu's architecture then let them develop and amd compiler (which i have to imagine they have an in house developed compiler).
i don't understand this complaint at all, one of the mandatory classes that all comp sci programs require some one desiring to get a b.s. in comp sci is a class on compiler design and the final project is that the student writes his own compiler. i'm sure amd must have people working for them that have master's and phd's in comp sci, you're telling me that no one at amd is capable of coding a compiler or modifying gcc? come on, it's a silly complaint.
as for the rest i'm certain that the claims are either true or mostly true, but that also doesn't change this fact: it seems to me that both amd and nvidia must be very scared of intel's upcoming cpu/gpu hybrid processor in order to sic the dogs on intel and that is good for the consumers.
amd has been dragging it's feet on gpgpu for a while now, first they said that by 2011 they would offer a processor that was a hybrid cpu/gpu called fusion, then they said that fusion refers to the complete platform featuring an amd cpu, ati video card and amd chipset, then they say that bulldozer will be a completely new architecture with smt features, that no longer has cores in the traditional sense, with an integrated gpu that will handle most of the floating point calculations, then they release a statement saying that while the floating point ops will eventually be offloaded to the gpu it won't be with bulldozer but with a processor that will be released in 3-5 years, the truth is that amd has zero interest in cpu/gpu integration, they are segregationists, it's against their financial interests to combine the gpu with the cpu into one kick ass processor, it would kill their video card business after they pumped all that money buying up ati and building fabs.
if anything amd is more guilty of trying to kill gpgpu than intel will ever be, nvidia is just hell bent on removing the cpu from the equation completely, just have it there to handle I/O to/from the graphics card and disk drives and have the gpu do all the work, so that fact of the matter is all 3 big players in this mess have ulterior motives that have little to do with what's best for consumers.
i personally hope that intel prevails because i firmly believe that their path offers the greatest benefit for consumers, but other than that if another player were to show up with technology that offered massive performance gains, i would jump on that bandwagon in a heart beat. -
Well maybe that's part of the explanation for trying to get cuda & x264 to work, I'll post the other which has to do with massive parallelization in the order of 20,000 threads. This is why they say code has to be re-written to take advantage of cuda. Eitherway, I'm sure the developers know what they are talking about on the x264 side, even if you dispute their knowlege of cuda architecture and programming. Anyway every month somebody comes around and thinks they have got it figured out, but they always disappear after a few days. Maybe you know a workaround that they don't ?Originally Posted by deadrats
This is from LordMulder, from the link I posted earlier:
http://developer.download.nvidia.com/compute/cuda/2_0/docs/NVIDIA_CUDA_Programming_Guide_2.0.pdfYou must think of the GPU as a massively parallel processor. So GPGPU (CUDA, Stream, OpenCL, etc) gives the programmer access to a massively parallel co-processor.
And we are not talking about four or eights threads here. We are talking about hundreds or even better thousands of threads that need to run on the GPU!
So if you want to leverage the theoretical processing power of a GPU, your problem must be highly parallelizeable and new algorithms are needed that scale to hundreds/thousands of threads.
Therefore not any problem is suitable for the GPU. There are inherently sequential problems that don't fit on the GPU at all!
The GPU cores are many, but they are very limited. Especially memory access to the (global) GPU memory is extremely slow, because it's not cached at all (except for texture memory).
Thus we must try to "hide" slow memory access with calculations, which means that we need much more GPU threads than we have GPU cores.
Well, each group/block of GPU cores has its own local "shared" memory that is fast, but the size of that per-block shared memory is small. Way too small for many things!
Also we can't sync the shared memories of different blocks, so whenever threads from different blocks need to "communicate", this needs to be done through the slow "global" memory.
Even organizing/synchronizing the threads within a block is a though task, because "bad" memory access patterns can slow down your GPU program significantly!
Last but not least the GPU cannot access the main/host memory at all. Hence the CPU program needs to upload all input data to the graphic's device first and later download all the results.
That "host <-> device" data transfer is a serious bottleneck and means that you cannot run "small" functions on the GPU, even if they are a lot faster there.
What worth is it to complete a calculation in 1 ms instead of 10 ms, but it takes 20 ms to upload/download the data to/from the graphic's device? Yes, it's completely useless!
So if we move parts of our program to the GPU, this must be significant parts with enough "work" to justify the communication delay. It's not trivial to find such parts in your software.
Remember: Those parts must also be highly parallelizable and efficient parallel algorithms for the individual problem must exists (or must be developed). -
@poisondeathray
and yet despite what lord mulder says, badaboom is an h264 encoder that runs entirely on the gpu and there is an open cl based gpu accelerated mpeg-2 encoder that sees a 50% jump in encoding speed:
http://www.engadget.com/2009/09/17/snow-leopards-grand-central-dispatch-and-opencl-boost-video-enc/
our dear "lord's" explanation is asinine on so many different levels that it boggles the mind, plane and simple. for one thing video encoding is one of the most parallelizable tasks currently out there, you can tackle the problem any number of ways:
1) deal with each frame individually, i.e. launch a separate thread for each frame
2) deal with each gop individually, i.e. launch a separate thread for each gop
3) launch a decode thread and an encode thread for every 10 seconds of film
there are any number of ways to parallelize video encoding, the claim that it's an inherently sequential task is ludicrous and tells me that no one should ever use any software that these guys develop, ever.
furthermore, as i already pointed out, gpu's thread dispatchers do most of the work, gpu "cores" are nothing like cpu cores, the programmer doesn't have to worry as much, if at all, about multi-threading his app, if these guys bothered to try and learn cuda programming or open cl programming they would know that.
lord mulder's and that other clown from x264, clearly have no idea what the hell they are talking about, none. they are a shining example of why gpgpu classes are graduate level courses available only at top notch engineering schools to people working on master's and phd's.
here's one last little tid-bit to chew on, most "knowledgeable" people claim that video filters are inherently a sequential task as a way of explaining why there are so few multi-threaded video filters available, well evidently it's not that inherently sequential because at least one developer has figured out how to do it:
http://www.thedeemon.com/articles/virtualdub_filters_and_multithreading.html
these guys take single threaded filters and manage to get them to run in parallel without recoding them.
what it boils down to is that there are programmers and then there are programmers... -
deadrats - many have claimed exactly what you have, and yet none have been able to port even a bit of x264 code to the cuda gpu api
Remember , his comments applies specifically to x264, badaboom was written from the ground up specifically for cuda. Don't confuse the subject
You might know a bit about gpu/cpu architecture, but these statements absolutely prove you know nothing about how x264 works, or video encoding in general. My brain just shut off to anything else you might have to say about video encoding. But I'll still listen your thoughts on gpu/cpu architecture.our dear "lord's" explanation is asinine on so many different levels that it boggles the mind, plane and simple. for one thing video encoding is one of the most parallelizable tasks currently out there, you can tackle the problem any number of ways:
1) deal with each frame individually, i.e. launch a separate thread for each frame
2) deal with each gop individually, i.e. launch a separate thread for each gop
3) launch a decode thread and an encode thread for every 10 seconds of film
The fact is, in order for x264 to run on cuda efficiently - it has to be rewritten. If you think it sucks, or is bad code, that's another issue entirely.
I've examined every so called "gpu" encoder so far, and they all suck. I'm not even interested until they gain a semblance of quality - but that's another issue. We were discussing how x264 could be made to work with cuda
Think of all the software we have now, how much of it is well multithreaded ? Some tasks are amenable to be multithreaded, some are not.
Do you think it's as "easy" as you claim ? Are programmers just "lazy" across the board? Even paid ones?
How many years have we had SMT capability, and yet only so few apps are multithreaded? And even those are poorly multithreaded. Hell x264 is just about the only one that scales linearly with a slope=1 with more cores. Almost all the other applications, even 3dsmax don't scale nearly as well! -
The fast GPU based encoders only perform the easily parallelizable functions. They don't do all the hard non-parallelizable operations. That's why they all suck.
-
all that tells me is that x264 is poorly written to begin with, that is all.Originally Posted by poisondeathray
i'll do you a favor and wait for you to turn your brain back on.....still rebooting? i'll wait some more....Originally Posted by poisondeathray
back up? good, now how about you tell me what exactly you didn't like about my comments on how to parallelize video encoding.
video is inherently just a data stream, a collection of bits, that represent a visual portrayal of a sequence of events. why do you find it so distasteful that i suggest that you treat each frame individually, or each gop individually by assigning a separate thread to each one? i'm fairly certain i know what your objection is, i just want you to say it first and then i'll explain why from a programming standpoint you are wrong, lay it on me.
really? i never would have figured that out if you hadn't told me, thanks. here's a bit of trivia for you, when people say to "port" code over to another platform, that's what they mean, to rewrite it, either in whole or in part.Originally Posted by poisondeathray
now, i know you take what the x264 developers say as gospel, but do yourself a favor and download the white paper labeled "parallel processing with cuda":
http://www.nvidia.com/object/cuda_what_is.html
and pay close attention to the part titled: "cuda automatically manages threads" and "hiding the processors" and you'll understand why i say both mulder and that other dude with the indian sounding name (i don't remember his name of the top of my head, he's an x264 developer i think) are one step above a trained chimp.
yes, especially the paid ones, they are the laziest mother f*ckers you will ever come across, every last one of them. why do you think there's so many buggy apps out there? why do you think that so many companies license main concept's encoder or why so many games use the same engine that they licensed from someone else.Originally Posted by poisondeathray
because every last of of those f*ckers is a lazy piece of sh*t, that's why. the only ones that can conceivably be called not lazy are the people that write open source code either as a hobby or because they believe in it, but most of them are either losers or crappy programmers, pure monkey spunk that will never know the touch of a woman.
x264 scales because they do what i outlined in my previous post which you seemed to find distasteful, they segment the video stream in chunks, say you configure it to launch 2 threads, it cuts the stream in half and one thread works on the first half of the video stream and the other thread works on the second half of the stream and then concatenates the results, they do this all the way up to 16 threads, which seems to be a hard coded limit set by the x264 developers themselves. i remember someone making the claim that this process invariably resulted in the degradation of quality at the point of segmentation, but i never understood that claim, digital video is nothing more than a collection of electrical states, when you segment video digitally what you are actually doing is simply working on a group of electrical states at a time and then you are putting them back into place, i don't see how the data stream itself (which is what video on a computer basically is, just a data stream) can possibly be compromised. i can understand when dealing with film but not when dealing with a bunch of 1's and 0's.Originally Posted by poisondeathray
as for 3dsmax's scaling, it's because it's not a fish, just kidding, it's because when you are working with 3dsmax you are only dealing with 1 frame at a time, thus you need to figure out how to break said frame up into various pieces.
btw, have you ever tried out that benchmark cinebench, the one where you render a single hi res picture using multiple threads? if you can render a single picture using multiple threads, via slices, then why can't you apply the same technique to a single frame of video? inherently video is a collection of pictures, admittedly using a different compression scheme but a picture none the less. -
Intel just cancelled its graphics display Larrabee project last week. Maybe it plans to buy NVIDIA?
Recommends: Kiva.org - Loans that change lives.
http://www.kiva.org/about -
nvidia would never even consider selling it's assets to intel, intel may be inclined to attempt a hostile takeover but that would really make the FTC and SEC crawl up intel's ass and stay there.Originally Posted by edDV
no, larrabee was canceled for for a number of reasons:
intel initially envisioned the gaming industry, and 3d graphics in general, moving to ray tracing which is easily parallelizable (<-still not sure that's a word) and runs quite well on x86 hardware. they figured that would be a great way to eliminate both nvidia and amd's ati division as competitors. then they realized 2 things:
an add in card that features 48+ x86 cores would effectively kill their cpu business, who would bother upgrading to faster cpu's, new motherboards with new chipsets and new ram if you could just spend about $200 (i think that was the floated around target price for larrabee) and get 48 fully programmable x86 cores?
now there are those that will try to counter with the tired old cliche of "well just because you have more cores the software still needs to be able to use it" but that comes from people that have never written a line of code in their lives. the fact of the matter is this, intel themselves created a compiler that would automatically multi-thread code for the programmer, namely the intel compiler.
this compiler version was released back when the first hyper-threaded P4's hit retail as a way to help programmers that may not have experience with threaded programming take advantage of the P4's architecture, and the compiler worked quite well. the problem is that there seems to be a lot of inertia within the programming community, they just don't like change at all and tend to stick with the tools they have been using all along, thus those that were visual c users remained loyal to microsoft, the open source community stuck with gcc, borland users stayed with borland and pascal programmers didn't really have too many options since intel never released a pascal compiler and thus stuck with any of the various pascal compilers out there.
this however would not be the case with larrabee, this time around we have the open cl frame work, a larrabee like product could easily be taken advantage of by programmers with out having to drive themselves crazy trying to figure out how to keep 48+ threads in flight at any one time.
then there's this reality: gpu's already capable of a much greater degree of parallelization than larrabee would ever have been, it's much better to integrate the gpu into the cpu and accomplish the same thing with regards to amd and nvidia that you wanted to do all along, plus give your customers the performance you demand plus ensure that your forced upgrade business plan stays intact, basically everyone except amd and nvidia, and maybe a few customers, win.
it should be noted that intel did deliver about a hundred 100 core cpu's to research departments at various universities around the country so that they can study and learn how to more efficiently write multi-threaded code. -
Before you jump to criticize, maybe you should understand why this is. Yes, x264 can be re-written, but then you would have equivalent quality and speed to the crappy gpu encoders! You would lose all the benefit, with no gain.all that tells me is that x264 is poorly written to begin with, that is all.poisondeathray wrote:
deadrats - many have claimed exactly what you have, and yet none have been able to port even a bit of x264 code to the cuda gpu api
Because your posts indicate that you aren't very familiar with how video ENcoding works. Haven't you learned anything from our little encoder tests? Why did your videos look so shitty? Go back and read, the basic concepts are there.i'll do you a favor and wait for you to turn your brain back on.....still rebooting? i'll wait some more....poisondeathray wrote:
You might know a bit about gpu/cpu architecture, but these statements absolutely prove you know nothing about how x264 works, or video encoding in general. My brain just shut off to anything else you might have to say about video encoding. But I'll still listen your thoughts on gpu/cpu architecture.
back up? good, now how about you tell me what exactly you didn't like about my comments on how to parallelize video encoding.
video is inherently just a data stream, a collection of bits, that represent a visual portrayal of a sequence of events. why do you find it so distasteful that i suggest that you treat each frame individually, or each gop individually by assigning a separate thread to each one? i'm fairly certain i know what your objection is, i just want you to say it first and then i'll explain why from a programming standpoint you are wrong, lay it on me.
Video consists of I-frames, P-frames, and B-frames , and long GOP formats use both Intra-frame and Inter-frame predictive compression techniques. They code differences between frames. Video uses "frames", but you don't process individual frames, modern encoders look at macroblocks. And these macroblocks, when using h.264 can be 16x16, 8x8, 4x4. You use all these words, but I don't think you understand what they really mean. If you understood these basic concepts, you would understand why this x264 or any decent modern encoder won't work with cuda.
1) Dynamic frametype placement, GOP size
You would have to "dumb down" x264 in order for it to work with cuda. With efficient encoders such as x264, there is dynamic frametype placement, and variable GOP sizes. e.g. a "whip pan" might place 10 I-frames in a row, but a slow pan or static shot might be 300 frames long between keyframes. So you cannot know ahead of time how to divide up your video and spawn "x" number of threads according to how many "units" your GPU has available - you don't know where or what the GOP's look like ahead of time. This becomes an allocation issue as you have idle units, and extra resources have to be wasted on allocation and optimization.
Frametype allocation is variable with good encoders. Instead of a set IPPB, or IPP etc.., you can have virtually any combination. The problem with fixed GOP size and fixed frametype is you get a mismatch between source complexity and encoding quality. e.g. If a complex scene change needs a high weighted I-frame to make it look normal, but the fixed GOP and frame placement assigns a B-frame - you have serious quality issues on the frame - and you do see this on the Cuda encodes. You also see this with hardware encoders such as camcorders under content complexity situations - the entire scene breaks down. We saw this with your encodes in that comparison thread.
B-frames are bidirectional (forward and back) and can actually serve as b-pyramid references in either direction. You can't know ahead of time whether a frame will belong to one GOP or another. If you look at the low quality GPU baseline encoders, they get around this issue by not using b-frames at all, which we know is a big drop in efficiency
Sure, you could dumb it down and used a fixed GOP size and fixed frametype allocation, eliminate B-frames - but that lowers quality and efficiency. Go back and look at some of your encoded examples in that comparison thread that had no b-frames with fixed GOP, and the other that was Intra only.
2) Many of the processes are serial, and some of the code can't run in parallel.
Motion estmation and motion paths - think of a car going to A -> B -> C -> D -> E . Interframe compression code differences between frames and use prediction algorithms. The car doesn't "teleport" from A to E. You lose a lot of efficiency by coding "E" before taking into account similarities that exist between A,B,C,D. And if "C" was assigned to be on a GOP boundary you lose even more efficiency. Current algorithms like SATD, Hadamard Transform and brute force vector analyses are not optimized for parallelization.
Search radii - larger is more accurate and results in better coding efficiency but you run into parallization issues with overlap boundaries and cutting off vectors abruptly (how can you evenly delineate where a motion vector ends and distribute the work ahead of time in parallel units?). There is content variability e.g. A static scene has no motion vectors, but a thrown baseball would have both intraframe and interframe components. How do you divide it up ahead of time?
CABAC - entropy coding is inherently serial by nature. CABAC alone accounts for 20-30% encoding efficiency. Guess what? Baseline GPU encoders don't use it because they can't.
Intraframe predictive techniques are largely serial. h.264 uses pixel, even half and quarter pixel estimation. The way they are currently written relies on what is present. i.e. you can't jump ahead of the queue without examining what you already have within a frame as reference (you need a starting point, other wise you lose efficiency)
Now there's LOTS of room for improvement. And yes, there are some grad and phd students working on intraframe and interframe parallelization for all these concepts - both for x264 and in general. There are several published papers, but none have had much success solving these issues. And even if they could improve those issues, fundamentally you still have problems with #1 above and spatial range.
That's great, but none of it applies to this discussion. If you've understood anything from above, you would understand why cuda strategy doesn't work for decent video encoders. Who's the chimp now?now, i know you take what the x264 developers say as gospel, but do yourself a favor and download the white paper labeled "parallel processing with cuda":
http://www.nvidia.com/object/cuda_what_is.html
and pay close attention to the part titled: "cuda automatically manages threads" and "hiding the processors" and you'll understand why i say both mulder and that other dude with the indian sounding name (i don't remember his name of the top of my head, he's an x264 developer i think) are one step above a trained chimp.
ok good point
yes, especially the paid ones, they are the laziest mother f*ckers you will ever come across, every last one of them. why do you think there's so many buggy apps out there? why do you think that so many companies license main concept's encoder or why so many games use the same engine that they licensed from someone else.
because every last of of those f*ckers is a lazy piece of sh*t, that's why. the only ones that can conceivably be called not lazy are the people that write open source code either as a hobby or because they believe in it, but most of them are either losers or crappy programmers, pure monkey spunk that will never know the touch of a woman.
But what is specifically "crappy" about x264 programming? how could you improve it? at least try to make your critcisms valid instead of name calling. Nothing you've said about video encoding has had any validity so far. You don't understand it , so there's no way you can explain how to integrate x264 with cuda
I can tell you from a user standpoint x264 is the best in terms of top quality, speed at a given level of quality, configurability. Name something that gives you better results - free or paid.
Nope. Old video encoders do that circa 1980 do that. GPU and fixed GOP/fixed frametype allocation encoders do that. x264 and decent encoders do not. I've explained this above
x264 scales because they do what i outlined in my previous post which you seemed to find distasteful, they segment the video stream in chunks, say you configure it to launch 2 threads, it cuts the stream in half and one thread works on the first half of the video stream and the other thread works on the second half of the stream and then concatenates the results,
Nope. The issue of scaling and quality deals with slice and GOP boundaries, and variability of source content. You can't divide up "nicely" because you disrupt motion vectors and GOP sizes when you make randomly assignments and allocations. e.g. if you decide to use 4 slices on a intra frame , unless the video was exactly 4 evenly sized rectangles with no motion, you lose effiency at the boundary regions - because the motion vector might have crossed the boundary. Now throw in the fact that there are different sized macroblocks and you have a more complex jigsaw puzzle. For interframe, if you randomly decide 5 frames / 5 frames split, if motion data from the first group traverses into the second group, you lose efficiency. So for both Inter and Intra, you lose more efficiency with more threads. (Efficiency of course meaning, in video terms is quality at a certain bitrate.)they do this all the way up to 16 threads, which seems to be a hard coded limit set by the x264 developers themselves. i remember someone making the claim that this process invariably resulted in the degradation of quality at the point of segmentation, but i never understood that claim, digital video is nothing more than a collection of electrical states, when you segment video digitally what you are actually doing is simply working on a group of electrical states at a time and then you are putting them back into place, i don't see how the data stream itself (which is what video on a computer basically is, just a data stream) can possibly be compromised. i can understand when dealing with film but not when dealing with a bunch of 1's and 0's.
Again you are wrong. You have absolutely no clue how it works. Modern video encoding doesn't work on individual frames. Macroblocks, interframe and intraframe compression. See above. blah...blahas for 3dsmax's scaling, it's because it's not a fish, just kidding, it's because when you are working with 3dsmax you are only dealing with 1 frame at a time, thus you need to figure out how to break said frame up into various pieces.
btw, have you ever tried out that benchmark cinebench, the one where you render a single hi res picture using multiple threads? if you can render a single picture using multiple threads, via slices, then why can't you apply the same technique to a single frame of video? inherently video is a collection of pictures, admittedly using a different compression scheme but a picture none the less.
Now you will be about the umpteenth person to drop by and make the same suggestions. If you have something constructive, by all means make a suggestion or write a patch or improve an algorithm. They hire grad students in the summer for the "summer of code". I suggest you post on Doom9, Doom10, or the IRC channel, as the developers know the intricacies well. But I seriously think you'd get laughed at, at least until you get the basic video concepts down.
 Quote
QuoteSimilar Threads
-
Review this system.... (revision 2.0)
By Engineering in forum ComputerReplies: 14Last Post: 17th Dec 2009, 10:54 -
a top quality powerlevel website
By xgame in forum Off topicReplies: 0Last Post: 2nd Sep 2007, 22:13